issues
3 rows where state = "open" and user = 703554 sorted by updated_at descending
This data as json, CSV (advanced)
Suggested facets: created_at (date), updated_at (date)
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at ▲ | closed_at | author_association | active_lock_reason | draft | pull_request | body | reactions | performed_via_github_app | state_reason | repo | type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 267628781 | MDU6SXNzdWUyNjc2Mjg3ODE= | 1650 | Low memory/out-of-core index? | alimanfoo 703554 | open | 0 | 17 | 2017-10-23T11:13:06Z | 2023-08-29T11:43:19Z | CONTRIBUTOR | Has anyone considered implementing an index for monotonic data that does not require loading all values into main memory? Motivation: We have data where first dimension can be length ~100,000,000, and coordinates for this dimension are stored as 32-bit integers. Currently if we used a pandas Index this would cast to 64-bit integers, and the index would require ~1GB RAM. This isn't enormous, but isn't negligible for people working on modest computers. Our use cases are simple, typically we only ever need to locate a slice of this dimension from a pair of coordinates, i.e., we only need to do binary search (bisect) on the coordinates. To achieve binary search in fact there is no need at all to load the coordinate values into memory, they could be left on disk (e.g., in HDF5 or Zarr dataset) and still achieve perfectly adequate performance for our needs. This is of course also relevant to pandas but thought I'd post here as I know there have been some discussions about how to handle indexes when working with larger datasets via dask. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1650/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 621078539 | MDU6SXNzdWU2MjEwNzg1Mzk= | 4079 | Unnamed dimensions | alimanfoo 703554 | open | 0 | 12 | 2020-05-19T15:33:48Z | 2023-02-18T16:51:14Z | CONTRIBUTOR | I'd like to build an xarray dataset with a couple of dozen variables. All of these variables share a common first dimension, which I want to name. Some of the arrays have other dimensions, but none of those dimensions are in common with any other arrays, and I don't want to ever refer to them by name. Currently IIUC xarray requires that all dimensions are named, which forces me to invent names for all these other dimensions. This ends up with a dataset with lots of noise dimensions in it. I tried using Is there a way to create arrays and datasets with unnamed dimensions? Thanks in advance. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4079/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
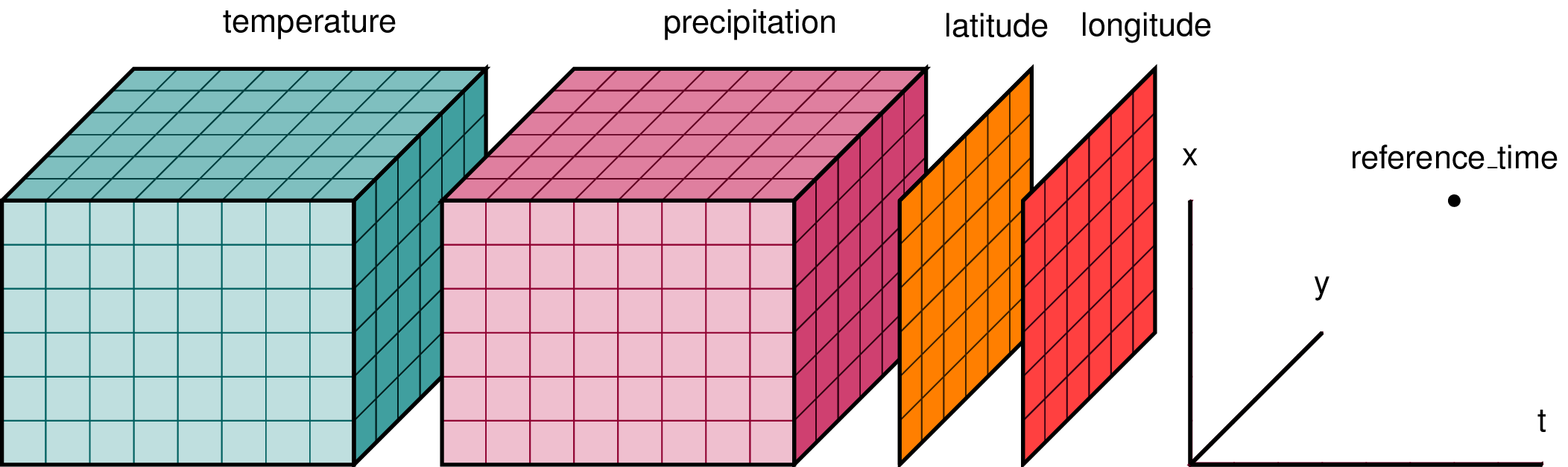
| 1300534066 | I_kwDOAMm_X85NhJMy | 6771 | Explaining xarray in a single picture | alimanfoo 703554 | open | 0 | 5 | 2022-07-11T10:47:55Z | 2022-07-20T09:41:07Z | CONTRIBUTOR | What is your issue?Hi folks, I'm working on a mini-tutorial introducing xarray for some folks in our genetics community and noticed something slightly confusing about the typical pictures used to help describe what xarray is for. E.g., this picture is commonly used:
I get that temperature and precipitation are data variables which have been measured over the three dimensions of latitude, longitude and time. But I'm slightly confused here because I would've thought that latitude and longitude would be 1-dimensional coordinate variables, yet they are drawn as 2-D arrays? Elsewhere I found a slightly different version:
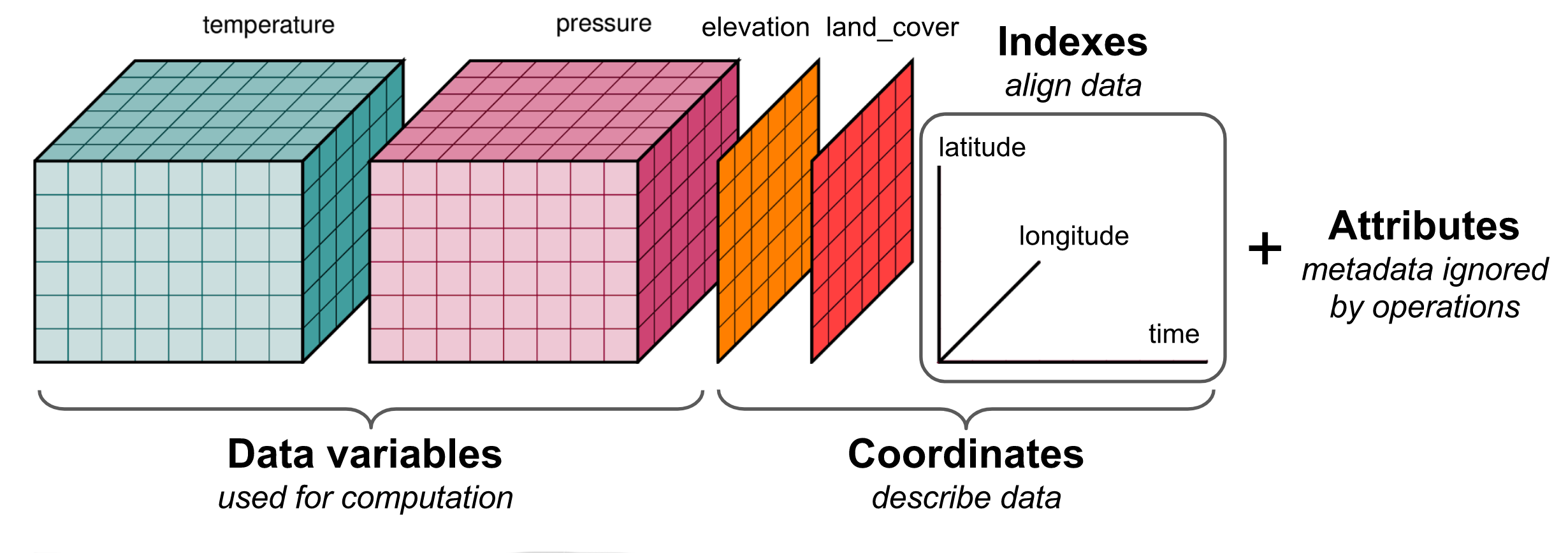
This makes more sense to me, because here the 2-D arrays have been labeled as "elevation" and "land_cover", and thus these are variables which are measured over the dimensions of latitude and longitude but not time, hence 2-D. Also, here latitude, longitude and time are shown labelling the dimensions, which again makes a bit more sense. However, "elevantion" and "land_cover" are included within the "coordinates" bracket, and I would have thought that elevation and land_cover would be more naturally considered as data variables? Feel free to close/ignore/set me straight if I'm missing something here, but just thought I would raise to say that I was looking for a simple picture to help me explain what xarray is all about for newcomers and found these existing pictures a little confusing. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/6771/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue |
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[active_lock_reason] TEXT,
[draft] INTEGER,
[pull_request] TEXT,
[body] TEXT,
[reactions] TEXT,
[performed_via_github_app] TEXT,
[state_reason] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);