issues
9 rows where state = "open" and user = 1200058 sorted by updated_at descending
This data as json, CSV (advanced)
Suggested facets: comments, created_at (date), updated_at (date)
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at ▲ | closed_at | author_association | active_lock_reason | draft | pull_request | body | reactions | performed_via_github_app | state_reason | repo | type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 595784008 | MDU6SXNzdWU1OTU3ODQwMDg= | 3945 | Implement `value_counts` method | Hoeze 1200058 | open | 0 | 3 | 2020-04-07T11:05:06Z | 2023-09-12T15:47:22Z | NONE | Implement MCVE Code Sample
Suggested API:
Expected Output
Problem DescriptionCurrently there is no existing equivalent to this method that I know in xarray. VersionsOutput of `xr.show_versions()`INSTALLED VERSIONS ------------------ commit: None python: 3.7.6 | packaged by conda-forge | (default, Jan 7 2020, 22:33:48) [GCC 7.3.0] python-bits: 64 OS: Linux OS-release: 5.3.11-1.el7.elrepo.x86_64 machine: x86_64 processor: byteorder: little LC_ALL: None LANG: en_US.UTF-8 LOCALE: en_US.UTF-8 libhdf5: 1.10.5 libnetcdf: 4.7.3 xarray: 0.15.0 pandas: 1.0.0 numpy: 1.17.5 scipy: 1.4.1 netCDF4: 1.5.3 pydap: None h5netcdf: 0.7.4 h5py: 2.10.0 Nio: None zarr: 2.4.0 cftime: 1.0.4.2 nc_time_axis: None PseudoNetCDF: None rasterio: None cfgrib: None iris: None bottleneck: None dask: 2.10.1 distributed: 2.10.0 matplotlib: 3.1.3 cartopy: None seaborn: 0.10.0 numbagg: None setuptools: 45.1.0.post20200119 pip: 20.0.2 conda: None pytest: 5.3.5 IPython: 7.12.0 sphinx: 2.0.1 |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3945/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 712217045 | MDU6SXNzdWU3MTIyMTcwNDU= | 4476 | Reimplement GroupBy.argmax | Hoeze 1200058 | open | 0 | 5 | 2020-09-30T19:25:22Z | 2023-03-03T06:59:40Z | NONE | Please implement Is your feature request related to a problem? Please describe.
Observed:
AttributeError Traceback (most recent call last) <ipython-input-84-15c199b0f7d4> in <module> ----> 1 da.groupby("g").argmax(dim="t") AttributeError: 'DataArrayGroupBy' object has no attribute 'argmax' ``` Describe the solution you'd like
Expected: Vector of length Workaround:
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4476/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
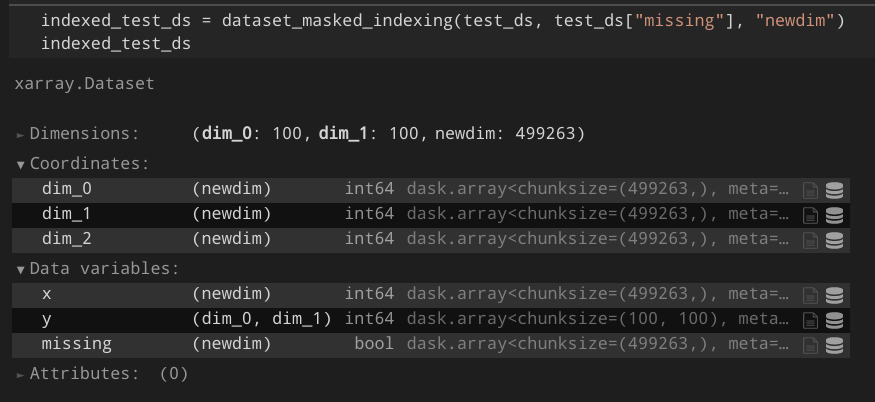
| 860418546 | MDU6SXNzdWU4NjA0MTg1NDY= | 5179 | N-dimensional boolean indexing | Hoeze 1200058 | open | 0 | 6 | 2021-04-17T14:07:48Z | 2021-07-16T17:30:45Z | NONE | Currently, the docs state that boolean indexing is only possible with 1-dimensional arrays: http://xarray.pydata.org/en/stable/indexing.html However, I often have the case where I'd like to convert a subset of an xarray to a dataframe.
Usually, I would call e.g.:
However, this approach is incredibly slow and memory-demanding, since it creates a MultiIndex of every possible coordinate in the array. Describe the solution you'd like
A better approach would be to directly allow index selection with the boolean array:
Additional context I created a proof-of-concept that works for my projects: https://gist.github.com/Hoeze/c746ea1e5fef40d99997f765c48d3c0d Some important lines are those: ```python def core_dim_locs_from_cond(cond, new_dim_name, core_dims=None) -> List[Tuple[str, xr.DataArray]]: [...] core_dim_locs = np.argwhere(cond.data) if isinstance(core_dim_locs, dask.array.core.Array): core_dim_locs = core_dim_locs.persist().compute_chunk_sizes() def subset_variable(variable, core_dim_locs, new_dim_name, mask=None): [...] subset = dask.array.asanyarray(variable.data)[mask] # force-set chunk size from known chunks chunk_sizes = core_dim_locs[0][1].chunks[0] subset._chunks = (chunk_sizes, *subset._chunks[1:]) ``` As a result, I would expect something like this:
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/5179/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 489825483 | MDU6SXNzdWU0ODk4MjU0ODM= | 3281 | [proposal] concatenate by axis, ignore dimension names | Hoeze 1200058 | open | 0 | 4 | 2019-09-05T15:06:22Z | 2021-07-08T17:42:53Z | NONE | Hi, I wrote a helper function which allows to concatenate arrays like I often need this to combine very different feature types. ```python from typing import Union, Tuple, List import numpy as np import xarray as xr def concat_by_axis(
darrs: Union[List[xr.DataArray], Tuple[xr.DataArray]],
dims: Union[List[str], Tuple[str]],
axis: int = None,
**kwargs
):
"""
Concat arrays along some axis similar to ``` Would it make sense to include this in xarray? |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3281/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 636512559 | MDU6SXNzdWU2MzY1MTI1NTk= | 4143 | [Feature request] Masked operations | Hoeze 1200058 | open | 0 | 1 | 2020-06-10T20:04:45Z | 2021-04-22T20:54:03Z | NONE | Xarray already has Logically, a sparse array is equal to a masked dense array.
They only differ in their internal data representation.
Therefore, I would propose to have a This would solve a number of problems: - No more conversion of int -> float - Explicit value for missingness - When stacking data with missing values, the missing values can be just dropped - When converting data with missing values to DataFrame, the missing values can be just dropped MCVE Code SampleAn example would be outer joins with slightly different coordinates (taken from the documentation): ```python
Non-masked outer join:```python
The masked version:```python
Related issue: https://github.com/pydata/xarray/issues/3955 |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4143/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 512879550 | MDU6SXNzdWU1MTI4Nzk1NTA= | 3452 | [feature request] __iter__() for rolling-window on datasets | Hoeze 1200058 | open | 0 | 2 | 2019-10-26T20:08:06Z | 2021-02-18T21:41:58Z | NONE | Currently, rolling() on a dataset does not return an iterator: MCVE Code Sample```python arr = xr.DataArray(np.arange(0, 7.5, 0.5).reshape(3, 5), dims=('x', 'y')) r = arr.to_dataset(name="test").rolling(y=3)
for label, arr_window in r:
print(label)
TypeError Traceback (most recent call last) <ipython-input-12-b1703cb71c1e> in <module> 3 4 r = arr.to_dataset(name="test").rolling(y=3) ----> 5 for label, arr_window in r: 6 print(label) TypeError: 'DatasetRolling' object is not iterable ``` Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3452/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 528060435 | MDU6SXNzdWU1MjgwNjA0MzU= | 3570 | fillna on dataset converts all variables to float | Hoeze 1200058 | open | 0 | 5 | 2019-11-25T12:39:49Z | 2020-09-15T15:35:04Z | NONE | MCVE Code Sample
Expected Output
Problem DescriptionI'd like to use Would it be possible to apply Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3570/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 566509807 | MDU6SXNzdWU1NjY1MDk4MDc= | 3775 | [Question] Efficient shortcut for unstacking only parts of dimension? | Hoeze 1200058 | open | 0 | 1 | 2020-02-17T20:46:03Z | 2020-03-07T04:53:05Z | NONE | Hi all, is there an efficient way to unstack only parts of a MultiIndex? Consider for example the following array:
Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3775/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 325661581 | MDU6SXNzdWUzMjU2NjE1ODE= | 2175 | [Feature Request] Visualizing dimensions | Hoeze 1200058 | open | 0 | 4 | 2018-05-23T11:22:29Z | 2019-07-12T16:10:23Z | NONE | Hi, I'm curious how you created your logo:
I'd like to create visualizations of the dimensions in my dataset similar to your logo. Having a functionality simplifying this task would be a very useful feature in xarray. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2175/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue |

Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[active_lock_reason] TEXT,
[draft] INTEGER,
[pull_request] TEXT,
[body] TEXT,
[reactions] TEXT,
[performed_via_github_app] TEXT,
[state_reason] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);