issues
81 rows where state = "closed" and user = 1197350 sorted by updated_at descending
This data as json, CSV (advanced)
Suggested facets: comments, created_at (date), updated_at (date), closed_at (date)
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at ▲ | closed_at | author_association | active_lock_reason | draft | pull_request | body | reactions | performed_via_github_app | state_reason | repo | type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1503046820 | I_kwDOAMm_X85Zlqyk | 7388 | Xarray does not support full range of netcdf-python compression options | rabernat 1197350 | closed | 0 | 22 | 2022-12-19T14:21:17Z | 2023-12-21T15:43:06Z | 2023-12-21T15:24:17Z | MEMBER | What is your issue?SummaryThe netcdf4-python API docs say the following
Although ...it appears that we silently ignores the Code example```python shape = (10, 20) chunksizes = (1, 10) encoding = { 'compression': 'zlib', 'shuffle': True, 'complevel': 8, 'fletcher32': False, 'contiguous': False, 'chunksizes': chunksizes } da = xr.DataArray( data=np.random.rand(*shape), dims=['y', 'x'], name="foo", attrs={"bar": "baz"} ) da.encoding = encoding ds = da.to_dataset() fname = "test.nc" ds.to_netcdf(fname, engine="netcdf4", mode="w") with xr.open_dataset(fname, engine="netcdf4") as ds1: display(ds1.foo.encoding) ```
In addition to showing that ProposalWe should align with the recommendation from the netcdf4 docs and support |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/7388/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 1983894219 | PR_kwDOAMm_X85e8V31 | 8428 | Add mode='a-': Do not overwrite coordinates when appending to Zarr with `append_dim` | rabernat 1197350 | closed | 0 | 3 | 2023-11-08T15:41:58Z | 2023-12-01T04:21:57Z | 2023-12-01T03:58:54Z | MEMBER | 0 | pydata/xarray/pulls/8428 | This implements the 1b option described in #8427.
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/8428/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 1983891070 | I_kwDOAMm_X852P8Z- | 8427 | Ambiguous behavior with coordinates when appending to Zarr store with append_dim | rabernat 1197350 | closed | 0 | 4 | 2023-11-08T15:40:19Z | 2023-12-01T03:58:56Z | 2023-12-01T03:58:55Z | MEMBER | What happened?There are two quite different scenarios covered by "append" with Zarr
This issue is about what should happen when using Here's the current behavior. ```python import xarray as xr import zarr ds1 = xr.DataArray( np.array([1, 2, 3]).reshape(3, 1, 1), dims=('time', 'y', 'x'), coords={'x': [1], 'y': [2]}, name="foo" ).to_dataset() ds2 = xr.DataArray( np.array([4, 5]).reshape(2, 1, 1), dims=('time', 'y', 'x'), coords={'x':[-1], 'y': [-2]}, name="foo" ).to_dataset() how concat works: data are alignedds_concat = xr.concat([ds1, ds2], dim="time") assert ds_concat.dims == {"time": 5, "y": 2, "x": 2} now do a Zarr appendstore = zarr.storage.MemoryStore() ds1.to_zarr(store, consolidated=False) we do not check that the coordinates are aligned--just that they have the same shape and dtypeds2.to_zarr(store, append_dim="time", consolidated=False) ds_append = xr.open_zarr(store, consolidated=False) coordinates data have been overwrittenassert ds_append.dims == {"time": 5, "y": 1, "x": 1} ...with the latest valuesassert ds_append.x.data[0] == -1 ``` Currently, we always write all data variables in this scenario. That includes overwriting the coordinates every time we append. That makes appending more expensive than it needs to be. I don't think that is the behavior most users want or expect. What did you expect to happen?There are a couple of different options we could consider for how to handle this "extending" situation (with
We currently do 1a. I propose to switch to 1b. I think it is closer to what users want, and it requires less I/O. Anything else we need to know?No response Environment
INSTALLED VERSIONS
------------------
commit: None
python: 3.11.6 | packaged by conda-forge | (main, Oct 3 2023, 10:40:35) [GCC 12.3.0]
python-bits: 64
OS: Linux
OS-release: 5.10.176-157.645.amzn2.x86_64
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: C.UTF-8
LANG: C.UTF-8
LOCALE: ('en_US', 'UTF-8')
libhdf5: 1.14.2
libnetcdf: 4.9.2
xarray: 2023.10.1
pandas: 2.1.2
numpy: 1.24.4
scipy: 1.11.3
netCDF4: 1.6.5
pydap: installed
h5netcdf: 1.2.0
h5py: 3.10.0
Nio: None
zarr: 2.16.0
cftime: 1.6.2
nc_time_axis: 1.4.1
PseudoNetCDF: None
iris: None
bottleneck: 1.3.7
dask: 2023.10.1
distributed: 2023.10.1
matplotlib: 3.8.0
cartopy: 0.22.0
seaborn: 0.13.0
numbagg: 0.6.0
fsspec: 2023.10.0
cupy: None
pint: 0.22
sparse: 0.14.0
flox: 0.8.1
numpy_groupies: 0.10.2
setuptools: 68.2.2
pip: 23.3.1
conda: None
pytest: 7.4.3
mypy: None
IPython: 8.16.1
sphinx: None
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/8427/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 350899839 | MDU6SXNzdWUzNTA4OTk4Mzk= | 2368 | Let's list all the netCDF files that xarray can't open | rabernat 1197350 | closed | 0 | 32 | 2018-08-15T17:41:13Z | 2023-11-30T04:36:42Z | 2023-11-30T04:36:42Z | MEMBER | At the Pangeo developers meetings, I am hearing lots of reports from folks like @dopplershift and @rsignell-usgs about netCDF datasets that xarray can't open. My expectation is that xarray doesn't have strong requirements on the contents of datasets. (It doesn't "enforce" cf compatibility for example; that's optional.) Anything that can be written to netCDF should be readable by xarray. I would like to collect examples of places where xarray fails. So far, I am only aware of one:
Are there other distinct cases? Please provide links / sample code of netCDF datasets that xarray can't read. Even better would be short code snippets to create such datasets in python using the netcdf4 interface. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2368/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 1935984485 | I_kwDOAMm_X85zZMdl | 8290 | Potential performance optimization for Zarr backend | rabernat 1197350 | closed | 0 | 0 | 2023-10-10T18:41:19Z | 2023-10-13T16:38:58Z | 2023-10-13T16:38:58Z | MEMBER | What is your issue?We have identified an inefficiency in the way the When accessing the array, the parent group of the array is read and used to open a new Zarr array. This is a relatively metadata-intensive operation for Zarr. It requires reading both the group metadata and the array metadata. Because of how this wrapper works, these operations currently happen every time data is read from the array. If we have a dask array wrapping the zarr array with thousands of chunks, these metadata operations will happen within every single task. For high latency stores, this is really bad. Instead, we should just reference the |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/8290/reactions",
"total_count": 6,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 2,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 357808970 | MDExOlB1bGxSZXF1ZXN0MjEzNzM2NTAx | 2405 | WIP: don't create indexes on multidimensional dimensions | rabernat 1197350 | closed | 0 | 7 | 2018-09-06T20:13:11Z | 2023-07-19T18:33:17Z | 2023-07-19T18:33:17Z | MEMBER | 0 | pydata/xarray/pulls/2405 |
This is just a start to the solution proposed in #2368. A surprisingly small number of tests broke in my local environment. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 401874795 | MDU6SXNzdWU0MDE4NzQ3OTU= | 2697 | read ncml files to create multifile datasets | rabernat 1197350 | closed | 0 | 18 | 2019-01-22T17:33:08Z | 2023-05-29T13:41:38Z | 2023-05-29T13:41:38Z | MEMBER | This issue was motivated by a recent conversation with @jdha regarding how they are preparing inputs for regional ocean models. They are currently using ncml with netcdf-java to consolidate and homogenize diverse data sources. But this approach doesn't play well with the xarray / dask stack. ncml is standard developed by Unidata for use with their netCDF-java library:
In addition to describing individual netCDF files, ncml can be used to annotate modifications to netCDF metadata (attributes, dimension names, etc.) and also to aggregate multiple files into a single logical dataset. This is what such an aggregation over an existing dimension looks like in ncml:
Obviously this maps very well to xarray's I think it would be great if we could support the ncml spec in xarray, allowing us to write code like
This idea has been discussed before in #893. Perhaps it's time has finally come. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2697/reactions",
"total_count": 7,
"+1": 7,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 1231184996 | I_kwDOAMm_X85JYmRk | 6588 | Support lazy concatenation *without dask* | rabernat 1197350 | closed | 0 | 2 | 2022-05-10T13:40:20Z | 2023-03-10T18:40:22Z | 2022-05-10T15:38:20Z | MEMBER | Is your feature request related to a problem?Right now, if I want to concatenate multiple datasets (e.g. as in In pseudocode: ```python ds1 = xr.open_dataset("some_big_lazy_source_1.nc") ds2 = xr.open_dataset("some_big_lazy_source_2.nc") item1 = ds1.foo[0, 0, 0] # lazily access a single item ds = xr.concat([ds1.chunk(), ds2.chunk()], "time") # only way to lazily concat trying to access the same item will now trigger loading of all of ds1item1 = ds.foo[0, 0, 0] yes I could use different chunks, but the point is that I should not have toarbitrarily choose chunks to make this work``` However, I am increasingly encountering scenarios where I would like to lazily concatenate datasets (without loading into memory), but also without the requirement of using dask. This would be useful, for example, for creating composite datasets that point back to an OpenDAP server, preserving the possibility of granular lazy access to any array element without the requirement of arbitrary chunking at an intermediate stage. Describe the solution you'd likeI propose to extend our LazilyIndexedArray classes to support simple concatenation and stacking. The result of applying concat to such arrays will be a new LazilyIndexedArray that wraps the underlying arrays into a single object. The main difficulty in implementing this will probably be with indexing: the concatenated array will need to understand how to map global indexes to the underling individual array indexes. That is a little tricky but eminently solvable. Describe alternatives you've consideredThe alternative is to structure your code in a way that avoids needing to lazily concatenate arrays. That is what we do now. It is not optimal. Additional contextNo response |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/6588/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 1260047355 | I_kwDOAMm_X85LGsv7 | 6662 | Obscure h5netcdf http serialization issue with python's http.server | rabernat 1197350 | closed | 0 | 6 | 2022-06-03T15:28:15Z | 2022-06-04T22:13:05Z | 2022-06-04T22:13:05Z | MEMBER | What is your issue?In Pangeo Forge, we try to test our ability to read data over http. This often surfaces edge cases involving xarray and fsspec. This is one such edge case. However, it is kind of important, because it affects our ability to reliably test http-based datasets using python's built-in http server. Here is some code that:
- Creates a tiny dataset on disk
- Serves it over http via As you can see, this works with a local file, but not with the http file, with h5py raising a checksum-related error. ```python import fsspec import xarray as xr from pickle import dumps, loads ds_orig = xr.tutorial.load_dataset('tiny') ds_orig fname = 'tiny.nc' ds_orig.to_netcdf(fname, engine='netcdf4') now start an http server in a terminal in the same working directory$ python -m http.serverdef open_pickle_and_reload(path): with fsspec.open(path, mode='rb') as fp: with xr.open_dataset(fp, engine='h5netcdf') as ds1: pass open_pickle_and_reload(fname) # works url = f'http://127.0.0.1:8000/{fname}' open_pickle_and_reload(url) # OSError: Unable to open file (incorrect metadata checksum after all read attempts) ``` full traceback``` --------------------------------------------------------------------------- KeyError Traceback (most recent call last) ~/Code/xarray/xarray/backends/file_manager.py in _acquire_with_cache_info(self, needs_lock) 198 try: --> 199 file = self._cache[self._key] 200 except KeyError: ~/Code/xarray/xarray/backends/lru_cache.py in __getitem__(self, key) 52 with self._lock: ---> 53 value = self._cache[key] 54 self._cache.move_to_end(key) KeyError: [<class 'h5netcdf.core.File'>, (<File-like object HTTPFileSystem, http://127.0.0.1:8000/tiny.nc>,), 'r', (('decode_vlen_strings', True), ('invalid_netcdf', None))] During handling of the above exception, another exception occurred: OSError Traceback (most recent call last) <ipython-input-2-195ac3fcdb43> in <module> 24 open_pickle_and_reload(fname) # works 25 url = f'[http://127.0.0.1:8000/{fname}'](http://127.0.0.1:8000/%7Bfname%7D'%3C/span%3E) ---> 26 open_pickle_and_reload(url) # OSError: Unable to open file (incorrect metadata checksum after all read attempts) <ipython-input-2-195ac3fcdb43> in open_pickle_and_reload(path) 20 # pickle it and reload it 21 ds2 = loads(dumps(ds1)) ---> 22 ds2.load() # works 23 24 open_pickle_and_reload(fname) # works ~/Code/xarray/xarray/core/dataset.py in load(self, **kwargs) 687 for k, v in self.variables.items(): 688 if k not in lazy_data: --> 689 v.load() 690 691 return self ~/Code/xarray/xarray/core/variable.py in load(self, **kwargs) 442 self._data = as_compatible_data(self._data.compute(**kwargs)) 443 elif not is_duck_array(self._data): --> 444 self._data = np.asarray(self._data) 445 return self 446 ~/Code/xarray/xarray/core/indexing.py in __array__(self, dtype) 654 655 def __array__(self, dtype=None): --> 656 self._ensure_cached() 657 return np.asarray(self.array, dtype=dtype) 658 ~/Code/xarray/xarray/core/indexing.py in _ensure_cached(self) 651 def _ensure_cached(self): 652 if not isinstance(self.array, NumpyIndexingAdapter): --> 653 self.array = NumpyIndexingAdapter(np.asarray(self.array)) 654 655 def __array__(self, dtype=None): ~/Code/xarray/xarray/core/indexing.py in __array__(self, dtype) 624 625 def __array__(self, dtype=None): --> 626 return np.asarray(self.array, dtype=dtype) 627 628 def __getitem__(self, key): ~/Code/xarray/xarray/core/indexing.py in __array__(self, dtype) 525 def __array__(self, dtype=None): 526 array = as_indexable(self.array) --> 527 return np.asarray(array[self.key], dtype=None) 528 529 def transpose(self, order): ~/Code/xarray/xarray/backends/h5netcdf_.py in __getitem__(self, key) 49 50 def __getitem__(self, key): ---> 51 return indexing.explicit_indexing_adapter( 52 key, self.shape, indexing.IndexingSupport.OUTER_1VECTOR, self._getitem 53 ) ~/Code/xarray/xarray/core/indexing.py in explicit_indexing_adapter(key, shape, indexing_support, raw_indexing_method) 814 """ 815 raw_key, numpy_indices = decompose_indexer(key, shape, indexing_support) --> 816 result = raw_indexing_method(raw_key.tuple) 817 if numpy_indices.tuple: 818 # index the loaded np.ndarray ~/Code/xarray/xarray/backends/h5netcdf_.py in _getitem(self, key) 58 key = tuple(list(k) if isinstance(k, np.ndarray) else k for k in key) 59 with self.datastore.lock: ---> 60 array = self.get_array(needs_lock=False) 61 return array[key] 62 ~/Code/xarray/xarray/backends/h5netcdf_.py in get_array(self, needs_lock) 45 class H5NetCDFArrayWrapper(BaseNetCDF4Array): 46 def get_array(self, needs_lock=True): ---> 47 ds = self.datastore._acquire(needs_lock) 48 return ds.variables[self.variable_name] 49 ~/Code/xarray/xarray/backends/h5netcdf_.py in _acquire(self, needs_lock) 180 181 def _acquire(self, needs_lock=True): --> 182 with self._manager.acquire_context(needs_lock) as root: 183 ds = _nc4_require_group( 184 root, self._group, self._mode, create_group=_h5netcdf_create_group /opt/miniconda3/envs/pangeo-forge-recipes/lib/python3.9/contextlib.py in __enter__(self) 117 del self.args, self.kwds, self.func 118 try: --> 119 return next(self.gen) 120 except StopIteration: 121 raise RuntimeError("generator didn't yield") from None ~/Code/xarray/xarray/backends/file_manager.py in acquire_context(self, needs_lock) 185 def acquire_context(self, needs_lock=True): 186 """Context manager for acquiring a file.""" --> 187 file, cached = self._acquire_with_cache_info(needs_lock) 188 try: 189 yield file ~/Code/xarray/xarray/backends/file_manager.py in _acquire_with_cache_info(self, needs_lock) 203 kwargs = kwargs.copy() 204 kwargs["mode"] = self._mode --> 205 file = self._opener(*self._args, **kwargs) 206 if self._mode == "w": 207 # ensure file doesn't get overridden when opened again /opt/miniconda3/envs/pangeo-forge-recipes/lib/python3.9/site-packages/h5netcdf/core.py in __init__(self, path, mode, invalid_netcdf, phony_dims, **kwargs) 719 else: 720 self._preexisting_file = mode in {"r", "r+", "a"} --> 721 self._h5file = h5py.File(path, mode, **kwargs) 722 except Exception: 723 self._closed = True /opt/miniconda3/envs/pangeo-forge-recipes/lib/python3.9/site-packages/h5py/_hl/files.py in __init__(self, name, mode, driver, libver, userblock_size, swmr, rdcc_nslots, rdcc_nbytes, rdcc_w0, track_order, fs_strategy, fs_persist, fs_threshold, fs_page_size, page_buf_size, min_meta_keep, min_raw_keep, locking, **kwds) 505 fs_persist=fs_persist, fs_threshold=fs_threshold, 506 fs_page_size=fs_page_size) --> 507 fid = make_fid(name, mode, userblock_size, fapl, fcpl, swmr=swmr) 508 509 if isinstance(libver, tuple): /opt/miniconda3/envs/pangeo-forge-recipes/lib/python3.9/site-packages/h5py/_hl/files.py in make_fid(name, mode, userblock_size, fapl, fcpl, swmr) 218 if swmr and swmr_support: 219 flags |= h5f.ACC_SWMR_READ --> 220 fid = h5f.open(name, flags, fapl=fapl) 221 elif mode == 'r+': 222 fid = h5f.open(name, h5f.ACC_RDWR, fapl=fapl) h5py/_objects.pyx in h5py._objects.with_phil.wrapper() h5py/_objects.pyx in h5py._objects.with_phil.wrapper() h5py/h5f.pyx in h5py.h5f.open() OSError: Unable to open file (incorrect metadata checksum after all read attempts) (external_url) ```Strangely, a similar workflow does work with http files hosted elsewhere, e.g.
This suggests there is something peculiar about python's I would appreciate any thoughts or ideas about what might be going on here (pinging @martindurant and @shoyer) xref: - https://github.com/pangeo-forge/pangeo-forge-recipes/pull/373 - https://github.com/pydata/xarray/issues/4242 - https://github.com/google/xarray-beam/issues/49 |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/6662/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 333312849 | MDU6SXNzdWUzMzMzMTI4NDk= | 2237 | why time grouping doesn't preserve chunks | rabernat 1197350 | closed | 0 | 30 | 2018-06-18T15:12:38Z | 2022-05-15T02:44:06Z | 2022-05-15T02:38:30Z | MEMBER | Code Sample, a copy-pastable example if possibleI am continuing my quest to obtain more efficient time grouping for calculation of climatologies and climatological anomalies. I believe this is one of the major performance bottlenecks facing xarray users today. I have raised this in other issues (e.g. #1832), but I believe I have narrowed it down here to a more specific problem. The easiest way to summarize the problem is with an example. Consider the following dataset
One non-dimension coordinate ( Now let's do a trivial groupby operation on Problem descriptionWhen grouping over a non-contiguous variable ( Expected OutputWe would like to preserve the original chunk structure of Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2237/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 413589315 | MDU6SXNzdWU0MTM1ODkzMTU= | 2785 | error decoding cftime time_bnds over opendap with pydap | rabernat 1197350 | closed | 0 | 2 | 2019-02-22T21:38:24Z | 2021-07-21T14:51:36Z | 2021-07-21T14:51:36Z | MEMBER | Code Sample, a copy-pastable example if possibleI try to load the following dataset over opendap with the pydap engine. It only works if I do decode_times=False
raises ``` IndexError Traceback (most recent call last) <ipython-input-52-df985a95e29e> in <module>() 1 #ds.time_bnds.load() ----> 2 xr.decode_cf(ds) ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/conventions.py in decode_cf(obj, concat_characters, mask_and_scale, decode_times, decode_coords, drop_variables) 459 vars, attrs, coord_names = decode_cf_variables( 460 vars, attrs, concat_characters, mask_and_scale, decode_times, --> 461 decode_coords, drop_variables=drop_variables) 462 ds = Dataset(vars, attrs=attrs) 463 ds = ds.set_coords(coord_names.union(extra_coords).intersection(vars)) ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/conventions.py in decode_cf_variables(variables, attributes, concat_characters, mask_and_scale, decode_times, decode_coords, drop_variables) 392 k, v, concat_characters=concat_characters, 393 mask_and_scale=mask_and_scale, decode_times=decode_times, --> 394 stack_char_dim=stack_char_dim) 395 if decode_coords: 396 var_attrs = new_vars[k].attrs ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/conventions.py in decode_cf_variable(name, var, concat_characters, mask_and_scale, decode_times, decode_endianness, stack_char_dim) 298 for coder in [times.CFTimedeltaCoder(), 299 times.CFDatetimeCoder()]: --> 300 var = coder.decode(var, name=name) 301 302 dimensions, data, attributes, encoding = ( ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/coding/times.py in decode(self, variable, name) 410 units = pop_to(attrs, encoding, 'units') 411 calendar = pop_to(attrs, encoding, 'calendar') --> 412 dtype = _decode_cf_datetime_dtype(data, units, calendar) 413 transform = partial( 414 decode_cf_datetime, units=units, calendar=calendar) ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/coding/times.py in _decode_cf_datetime_dtype(data, units, calendar) 116 values = indexing.ImplicitToExplicitIndexingAdapter( 117 indexing.as_indexable(data)) --> 118 example_value = np.concatenate([first_n_items(values, 1) or [0], 119 last_item(values) or [0]]) 120 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/core/formatting.py in first_n_items(array, n_desired) 94 from_end=False) 95 array = array[indexer] ---> 96 return np.asarray(array).flat[:n_desired] 97 98 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/numpy/core/numeric.py in asarray(a, dtype, order) 529 530 """ --> 531 return array(a, dtype, copy=False, order=order) 532 533 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/core/indexing.py in array(self, dtype) 630 631 def array(self, dtype=None): --> 632 self._ensure_cached() 633 return np.asarray(self.array, dtype=dtype) 634 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/core/indexing.py in _ensure_cached(self) 627 def _ensure_cached(self): 628 if not isinstance(self.array, NumpyIndexingAdapter): --> 629 self.array = NumpyIndexingAdapter(np.asarray(self.array)) 630 631 def array(self, dtype=None): ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/numpy/core/numeric.py in asarray(a, dtype, order) 529 530 """ --> 531 return array(a, dtype, copy=False, order=order) 532 533 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/core/indexing.py in array(self, dtype) 608 609 def array(self, dtype=None): --> 610 return np.asarray(self.array, dtype=dtype) 611 612 def getitem(self, key): ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/numpy/core/numeric.py in asarray(a, dtype, order) 529 530 """ --> 531 return array(a, dtype, copy=False, order=order) 532 533 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/core/indexing.py in array(self, dtype) 514 def array(self, dtype=None): 515 array = as_indexable(self.array) --> 516 return np.asarray(array[self.key], dtype=None) 517 518 def transpose(self, order): ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/conventions.py in getitem(self, key) 43 44 def getitem(self, key): ---> 45 return np.asarray(self.array[key], dtype=self.dtype) 46 47 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/numpy/core/numeric.py in asarray(a, dtype, order) 529 530 """ --> 531 return array(a, dtype, copy=False, order=order) 532 533 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/core/indexing.py in array(self, dtype) 514 def array(self, dtype=None): 515 array = as_indexable(self.array) --> 516 return np.asarray(array[self.key], dtype=None) 517 518 def transpose(self, order): ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/backends/pydap_.py in getitem(self, key) 24 def getitem(self, key): 25 return indexing.explicit_indexing_adapter( ---> 26 key, self.shape, indexing.IndexingSupport.BASIC, self._getitem) 27 28 def _getitem(self, key): ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/core/indexing.py in explicit_indexing_adapter(key, shape, indexing_support, raw_indexing_method) 785 if numpy_indices.tuple: 786 # index the loaded np.ndarray --> 787 result = NumpyIndexingAdapter(np.asarray(result))[numpy_indices] 788 return result 789 ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray/core/indexing.py in getitem(self, key) 1174 def getitem(self, key): 1175 array, key = self._indexing_array_and_key(key) -> 1176 return array[key] 1177 1178 def setitem(self, key, value): IndexError: too many indices for array ``` Strangely, I can overcome the error by first explicitly loading (or dropping) the I wish this would work without the I know this is a very obscure problem, but I thought I would open an issue to document. Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2785/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 745801652 | MDU6SXNzdWU3NDU4MDE2NTI= | 4591 | Serialization issue with distributed, h5netcdf, and fsspec (ImplicitToExplicitIndexingAdapter) | rabernat 1197350 | closed | 0 | 12 | 2020-11-18T16:18:42Z | 2021-06-30T17:53:54Z | 2020-11-19T15:54:38Z | MEMBER | This was originally reported by @jkingslake at https://github.com/pangeo-data/pangeo-datastore/issues/116. What happened: I tried to open a netcdf file over http using fsspec and the h5netcdf engine and compute data using dask.distributed. It appears that our What you expected to happen: Things would work. Indeed, I could swear this used to work with previous versions. Minimal Complete Verifiable Example: ```python import xarray as xr import fsspec from dask.distributed import Client example needs to use distributed to reproduce the bugclient = Client() url = 'https://storage.googleapis.com/ldeo-glaciology/bedmachine/BedMachineAntarctica_2019-11-05_v01.nc' raises the following error
Anything else we need to know?: One can work around this by using the netcdf4 library's new and undocumented ability to open files over http.
However, the fsspec + h5netcdf path should work! Environment: Output of <tt>xr.show_versions()</tt>``` INSTALLED VERSIONS ------------------ commit: None python: 3.8.6 | packaged by conda-forge | (default, Oct 7 2020, 19:08:05) [GCC 7.5.0] python-bits: 64 OS: Linux OS-release: 4.19.112+ machine: x86_64 processor: x86_64 byteorder: little LC_ALL: C.UTF-8 LANG: C.UTF-8 LOCALE: en_US.UTF-8 libhdf5: 1.10.6 libnetcdf: 4.7.4 xarray: 0.16.1 pandas: 1.1.3 numpy: 1.19.2 scipy: 1.5.2 netCDF4: 1.5.4 pydap: installed h5netcdf: 0.8.1 h5py: 2.10.0 Nio: None zarr: 2.4.0 cftime: 1.2.1 nc_time_axis: 1.2.0 PseudoNetCDF: None rasterio: 1.1.7 cfgrib: 0.9.8.4 iris: None bottleneck: 1.3.2 dask: 2.30.0 distributed: 2.30.0 matplotlib: 3.3.2 cartopy: 0.18.0 seaborn: None numbagg: None pint: 0.16.1 setuptools: 49.6.0.post20201009 pip: 20.2.4 conda: None pytest: 6.1.1 IPython: 7.18.1 sphinx: 3.2.1 ``` Also fsspec 0.8.4cc @martindurant for fsspec integration. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 836391524 | MDU6SXNzdWU4MzYzOTE1MjQ= | 5056 | Allow "unsafe" mode for zarr writing | rabernat 1197350 | closed | 0 | 1 | 2021-03-19T21:57:47Z | 2021-04-26T16:37:43Z | 2021-04-26T16:37:43Z | MEMBER | Curently, If I try to violate the one-to-many condition, I get an error
``` /srv/conda/envs/notebook/lib/python3.8/site-packages/xarray/backends/zarr.py in _determine_zarr_chunks(enc_chunks, var_chunks, ndim, name) 148 for dchunk in dchunks[:-1]: 149 if dchunk % zchunk: --> 150 raise NotImplementedError( 151 f"Specified zarr chunks encoding['chunks']={enc_chunks_tuple!r} for " 152 f"variable named {name!r} would overlap multiple dask chunks {var_chunks!r}. " NotImplementedError: Specified zarr chunks encoding['chunks']=(3,) for variable named 'foo' would overlap multiple dask chunks ((1, 1, 1),). This is not implemented in xarray yet. Consider either rechunking using In this case, the error is particularly frustrating because I'm not even writing any data yet. (Also related to #2300, #4046, #4380). There are at least two scenarios in which we might want to have more flexibility. 1. The case above, when we want to lazily initialize a Zarr array based on a Dataset, without actually computing anything. 2. The more general case, where we actually write arrays with many-to-many dask-chunk <-> zarr-chunk relationships For 1, I propose we add a new option like For 2, we could consider implementing locks. This probably has to be done at the Dask level. But is actually not super hard to deterministically figure out which chunks need to share a lock. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/5056/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 837243943 | MDExOlB1bGxSZXF1ZXN0NTk3NjA4NTg0 | 5065 | Zarr chunking fixes | rabernat 1197350 | closed | 0 | 32 | 2021-03-22T01:35:22Z | 2021-04-26T16:37:43Z | 2021-04-26T16:37:43Z | MEMBER | 0 | pydata/xarray/pulls/5065 |
This PR contains two small, related updates to how Zarr chunks are handled.
Both these touch the internal logic for how chunks are handled, so I thought it was easiest to tackle them with a single PR. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/5065/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 859945463 | MDU6SXNzdWU4NTk5NDU0NjM= | 5172 | Inconsistent attribute handling between netcdf4 and h5netcdf engines | rabernat 1197350 | closed | 0 | 3 | 2021-04-16T15:54:03Z | 2021-04-20T14:00:34Z | 2021-04-16T17:13:26Z | MEMBER | I have found a netCDF file that cannot be decoded by xarray via the h5netcdf engine but CAN be decoded via netCDF4. This could be considered an h5netcdf bug, but I thought I would raise it first here for visibility. This file will reproduce the bug
```python import netCDF4 import h5netcdf.legacyapi as netCDF4_h5 local_path = "cLeaf_Lmon_IPSL-CM6A-LR_abrupt-4xCO2_r1i1p1f1_gr_185001-214912.nc" with netCDF4_h5.Dataset(local_path, mode='r') as ncfile: print('h5netcdf:', ncfile['cLeaf'].getncattr("coordinates")) with netCDF4.Dataset(local_path, mode='r') as ncfile: #assert "coordinates" not in ncfile['cLeaf'].attrs print('netCDF4:', ncfile['cLeaf'].getncattr("coordinates")) ```
As we can see, we get an empty string We could:
- Fix it in xarray, but having special handling for this sort of Environment: Output of <tt>xr.show_versions()</tt>INSTALLED VERSIONS ------------------ commit: None python: 3.8.8 | packaged by conda-forge | (default, Feb 20 2021, 16:22:27) [GCC 9.3.0] python-bits: 64 OS: Linux OS-release: 4.19.150+ machine: x86_64 processor: x86_64 byteorder: little LC_ALL: C.UTF-8 LANG: C.UTF-8 LOCALE: en_US.UTF-8 libhdf5: 1.10.6 libnetcdf: 4.7.4 xarray: 0.17.0 pandas: 1.2.3 numpy: 1.20.2 scipy: 1.6.2 netCDF4: 1.5.6 pydap: installed h5netcdf: 0.10.0 h5py: 3.1.0 Nio: None zarr: 2.7.0 cftime: 1.4.1 nc_time_axis: 1.2.0 PseudoNetCDF: None rasterio: 1.2.1 cfgrib: 0.9.8.5 iris: None bottleneck: 1.3.2 dask: 2021.03.1 distributed: 2021.03.1 matplotlib: 3.3.4 cartopy: 0.18.0 seaborn: None numbagg: None pint: 0.17 setuptools: 49.6.0.post20210108 pip: 20.3.4 conda: None pytest: None IPython: 7.22.0 sphinx: Nonexref https://github.com/pangeo-forge/pangeo-forge/issues/105 |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/5172/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 548607657 | MDU6SXNzdWU1NDg2MDc2NTc= | 3689 | Decode CF bounds to coords | rabernat 1197350 | closed | 0 | 5 | 2020-01-12T18:23:26Z | 2021-04-19T03:32:26Z | 2021-04-19T03:32:26Z | MEMBER | CF conventions define Cell Boundaries and specify how to encode the presence of cell boundary variables in dataset attributes.
For example consider this dataset:
gives
Despite the presence of the bounds attributes ```
The variables Instead, we should decode all I cannot think of a single use case where one would want to treat these variables as data variables rather than coordinates. It would be easy to implement, but it is a breaking change. Not that this is just a proposal to move bounds variables to the coords part of the dataset. It does not address the more difficult / complex question of how to actually use the bounds for indexing or plotting operations (see e.g. #1475, #1613), although it could be a first step in that direction. Full ncdump of dataset
```
xarray.Dataset {
dimensions:
lat = 192 ;
lon = 288 ;
nbnd = 2 ;
time = 180 ;
variables:
float64 lat(lat) ;
lat:axis = Y ;
lat:bounds = lat_bnds ;
lat:standard_name = latitude ;
lat:title = Latitude ;
lat:type = double ;
lat:units = degrees_north ;
lat:valid_max = 90.0 ;
lat:valid_min = -90.0 ;
lat:_ChunkSizes = 192 ;
float64 lon(lon) ;
lon:axis = X ;
lon:bounds = lon_bnds ;
lon:standard_name = longitude ;
lon:title = Longitude ;
lon:type = double ;
lon:units = degrees_east ;
lon:valid_max = 360.0 ;
lon:valid_min = 0.0 ;
lon:_ChunkSizes = 288 ;
object time(time) ;
time:axis = T ;
time:bounds = time_bnds ;
time:standard_name = time ;
time:title = time ;
time:type = double ;
time:_ChunkSizes = 512 ;
object time_bnds(time, nbnd) ;
time_bnds:_ChunkSizes = [1 2] ;
float64 lat_bnds(lat, nbnd) ;
lat_bnds:units = degrees_north ;
lat_bnds:_ChunkSizes = [192 2] ;
float64 lon_bnds(lon, nbnd) ;
lon_bnds:units = degrees_east ;
lon_bnds:_ChunkSizes = [288 2] ;
float32 tas(time, lat, lon) ;
tas:cell_measures = area: areacella ;
tas:cell_methods = area: time: mean ;
tas:comment = near-surface (usually, 2 meter) air temperature ;
tas:description = near-surface (usually, 2 meter) air temperature ;
tas:frequency = mon ;
tas:id = tas ;
tas:long_name = Near-Surface Air Temperature ;
tas:mipTable = Amon ;
tas:out_name = tas ;
tas:prov = Amon ((isd.003)) ;
tas:realm = atmos ;
tas:standard_name = air_temperature ;
tas:time = time ;
tas:time_label = time-mean ;
tas:time_title = Temporal mean ;
tas:title = Near-Surface Air Temperature ;
tas:type = real ;
tas:units = K ;
tas:variable_id = tas ;
tas:_ChunkSizes = [ 1 192 288] ;
// global attributes:
:Conventions = CF-1.7 CMIP-6.2 ;
... [truncated]
```
Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3689/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 99836561 | MDU6SXNzdWU5OTgzNjU2MQ== | 521 | time decoding error with "days since" | rabernat 1197350 | closed | 0 | 20 | 2015-08-08T21:54:24Z | 2021-03-29T14:12:38Z | 2015-08-14T17:23:26Z | MEMBER | I am trying to use xray with some CESM POP model netCDF output, which supposedly follows CF-1.0 conventions. It is failing because the models time units are "'days since 0000-01-01 00:00:00". When calling open_dataset, I get the following error:
Full metadata for the time variable:
I guess this is a problem with the underlying netCDF4 num2date package? |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/521/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 288184220 | MDU6SXNzdWUyODgxODQyMjA= | 1823 | We need a fast path for open_mfdataset | rabernat 1197350 | closed | 0 | 19 | 2018-01-12T17:01:49Z | 2021-01-28T18:00:15Z | 2021-01-27T17:50:09Z | MEMBER | It would be great to have a "fast path" option for Implementing this would require some refactoring. @jbusecke mentioned that he had developed a solution for this (related to #1704), so maybe he could be the one to add this feature to xarray. This is also related to #1385. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1823/reactions",
"total_count": 9,
"+1": 9,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 753965875 | MDU6SXNzdWU3NTM5NjU4NzU= | 4631 | Decode_cf fails when scale_factor is a length-1 list | rabernat 1197350 | closed | 0 | 4 | 2020-12-01T03:07:48Z | 2021-01-15T18:19:56Z | 2021-01-15T18:19:56Z | MEMBER | Some datasets I work with have
In 0.16.2 (just released) and current master, it fails with this error ```AttributeError Traceback (most recent call last) <ipython-input-2-a0b01d6a314b> in <module> 2 attrs={'scale_factor': [0.01], 3 'add_offset': [1.0]}).to_dataset() ----> 4 xr.decode_cf(ds) ~/Code/xarray/xarray/conventions.py in decode_cf(obj, concat_characters, mask_and_scale, decode_times, decode_coords, drop_variables, use_cftime, decode_timedelta) 587 raise TypeError("can only decode Dataset or DataStore objects") 588 --> 589 vars, attrs, coord_names = decode_cf_variables( 590 vars, 591 attrs, ~/Code/xarray/xarray/conventions.py in decode_cf_variables(variables, attributes, concat_characters, mask_and_scale, decode_times, decode_coords, drop_variables, use_cftime, decode_timedelta) 490 and stackable(v.dims[-1]) 491 ) --> 492 new_vars[k] = decode_cf_variable( 493 k, 494 v, ~/Code/xarray/xarray/conventions.py in decode_cf_variable(name, var, concat_characters, mask_and_scale, decode_times, decode_endianness, stack_char_dim, use_cftime, decode_timedelta) 333 variables.CFScaleOffsetCoder(), 334 ]: --> 335 var = coder.decode(var, name=name) 336 337 if decode_timedelta: ~/Code/xarray/xarray/coding/variables.py in decode(self, variable, name) 271 dtype = _choose_float_dtype(data.dtype, "add_offset" in attrs) 272 if np.ndim(scale_factor) > 0: --> 273 scale_factor = scale_factor.item() 274 if np.ndim(add_offset) > 0: 275 add_offset = add_offset.item() AttributeError: 'list' object has no attribute 'item' ``` I'm very confused, because this feels quite similar to #4471, and I thought it was resolved #4485.
However, the behavior is different with How might I end up with a dataset with This problem would go away if we could resolve the discrepancies between the two engines' treatment of scalar attributes. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4631/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 753514595 | MDU6SXNzdWU3NTM1MTQ1OTU= | 4624 | Release 0.16.2? | rabernat 1197350 | closed | 0 | 6 | 2020-11-30T14:15:55Z | 2020-12-02T00:24:31Z | 2020-12-01T15:09:38Z | MEMBER | Looking at our what's new, we have quite a few important new features, as well as significant bug fixes. I propose we move towards releasing ~0.17.0~ 0.16.2 asap. (I have selfish motives for this, as I want to use the new features in production.) We can use this issue to track any PRs or issues we want to resolve before the next release. I personally am not aware of any major blockers, but other devs should feel free to edit this list.
cc @pydata/xarray |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4624/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 375663610 | MDU6SXNzdWUzNzU2NjM2MTA= | 2528 | display_width doesn't apply to dask-backed arrays | rabernat 1197350 | closed | 0 | 3 | 2018-10-30T19:49:05Z | 2020-09-30T06:17:17Z | 2020-09-30T06:17:17Z | MEMBER | The representation of dask-backed arrays in xarray's Code Sample, a copy-pastable example if possible
Problem description[this should explain why the current behavior is a problem and why the expected output is a better solution.] Expected OutputWe need to decide how to abbreviate dask arrays with something more concise. I'm not sure the best way to do this. Maybe
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2528/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 614814400 | MDExOlB1bGxSZXF1ZXN0NDE1MjkyMzM3 | 4047 | Document Xarray zarr encoding conventions | rabernat 1197350 | closed | 0 | 3 | 2020-05-08T15:29:14Z | 2020-05-22T21:59:09Z | 2020-05-20T17:04:02Z | MEMBER | 0 | pydata/xarray/pulls/4047 | When we implemented the Zarr backend, we made some ad hoc choices about how to encode NetCDF data in Zarr. At this stage, it would be useful to explicitly document this encoding. I decided to put it on the "Xarray Internals" page, but I'm open to moving if folks feel it fits better elsewhere. cc @jeffdlb, @WardF, @DennisHeimbigner |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4047/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 528884925 | MDU6SXNzdWU1Mjg4ODQ5MjU= | 3575 | map_blocks output inference problems | rabernat 1197350 | closed | 0 | 6 | 2019-11-26T17:56:11Z | 2020-05-06T16:41:54Z | 2020-05-06T16:41:54Z | MEMBER | I am excited about using
The problem is that many functions will simply error on size 0 data. As in the example below MCVE Code Sample```python import xarray as xr ds = xr.tutorial.load_dataset('rasm').chunk({'y': 20}) def calculate_anomaly(ds): # needed to workaround xarray's check with zero dimensions #if len(ds['time']) == 0: # return ds gb = ds.groupby("time.month") clim = gb.mean(dim='T') return gb - clim xr.map_blocks(calculate_anomaly, ds) ``` Raises ```KeyError Traceback (most recent call last) /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/dataset.py in _construct_dataarray(self, name) 1145 try: -> 1146 variable = self._variables[name] 1147 except KeyError: KeyError: 'time.month' During handling of the above exception, another exception occurred: AttributeError Traceback (most recent call last) /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/parallel.py in infer_template(func, obj, args, kwargs) 77 try: ---> 78 template = func(meta_args, **kwargs) 79 except Exception as e: <ipython-input-40-d7b2b2978c29> in calculate_anomaly(ds) 5 # return ds ----> 6 gb = ds.groupby("time.month") 7 clim = gb.mean(dim='T') /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/common.py in groupby(self, group, squeeze, restore_coord_dims) 656 return self._groupby_cls( --> 657 self, group, squeeze=squeeze, restore_coord_dims=restore_coord_dims 658 ) /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/groupby.py in init(self, obj, group, squeeze, grouper, bins, restore_coord_dims, cut_kwargs) 298 ) --> 299 group = obj[group] 300 if len(group) == 0: /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/dataset.py in getitem(self, key) 1235 if hashable(key): -> 1236 return self._construct_dataarray(key) 1237 else: /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/dataset.py in construct_dataarray(self, name) 1148 , name, variable = _get_virtual_variable( -> 1149 self._variables, name, self._level_coords, self.dims 1150 ) /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/dataset.py in _get_virtual_variable(variables, key, level_vars, dim_sizes) 157 else: --> 158 data = getattr(ref_var, var_name).data 159 virtual_var = Variable(ref_var.dims, data) AttributeError: 'IndexVariable' object has no attribute 'month' The above exception was the direct cause of the following exception: Exception Traceback (most recent call last) <ipython-input-40-d7b2b2978c29> in <module> 8 return gb - clim 9 ---> 10 xr.map_blocks(calculate_anomaly, ds) /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/parallel.py in map_blocks(func, obj, args, kwargs) 203 input_chunks = dataset.chunks 204 --> 205 template: Union[DataArray, Dataset] = infer_template(func, obj, args, *kwargs) 206 if isinstance(template, DataArray): 207 result_is_array = True /srv/conda/envs/notebook/lib/python3.7/site-packages/xarray/core/parallel.py in infer_template(func, obj, args, *kwargs) 80 raise Exception( 81 "Cannot infer object returned from running user provided function." ---> 82 ) from e 83 84 if not isinstance(template, (Dataset, DataArray)): Exception: Cannot infer object returned from running user provided function. ``` Problem DescriptionWe should try to imitate what dask does in Specifically: - We should allow the user to override the checks by explicitly specifying output dtype and shape - Maybe the check should be on small, rather than zero size, test data Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3575/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 499477363 | MDU6SXNzdWU0OTk0NzczNjM= | 3349 | Implement polyfit? | rabernat 1197350 | closed | 0 | 25 | 2019-09-27T14:25:14Z | 2020-03-25T17:17:45Z | 2020-03-25T17:17:45Z | MEMBER | Fitting a line (or curve) to data along a specified axis is a long-standing need of xarray users. There are many blog posts and SO questions about how to do it: - http://atedstone.github.io/rate-of-change-maps/ - https://gist.github.com/luke-gregor/4bb5c483b2d111e52413b260311fbe43 - https://stackoverflow.com/questions/38960903/applying-numpy-polyfit-to-xarray-dataset - https://stackoverflow.com/questions/52094320/with-xarray-how-to-parallelize-1d-operations-on-a-multidimensional-dataset - https://stackoverflow.com/questions/36275052/applying-a-function-along-an-axis-of-a-dask-array The main use case in my domain is finding the temporal trend on a 3D variable (e.g. temperature in time, lon, lat). Yes, you can do it with apply_ufunc, but apply_ufunc is inaccessibly complex for many users. Much of our existing API could be removed and replaced with apply_ufunc calls, but that doesn't mean we should do it. I am proposing we add a Dataarray method called ```python x_ = np.linspace(0, 1, 10) y_ = np.arange(5) a_ = np.cos(y_) x = xr.DataArray(x_, dims=['x'], coords={'x': x_}) a = xr.DataArray(a_, dims=['y']) f = a*x p = f.polyfit(dim='x', deg=1) equivalent numpy codep_ = np.polyfit(x_, f.values.transpose(), 1) np.testing.assert_allclose(p_[0], a_) ``` Numpy's polyfit function is already vectorized in the sense that it accepts 1D x and 2D y, performing the fit independently over each column of y. To extend this to ND, we would just need to reshape the data going in and out of the function. We do this already in other packages. For dask, we could simply require that the dimension over which the fit is calculated be contiguous, and then call map_blocks. Thoughts? |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3349/reactions",
"total_count": 9,
"+1": 9,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 361858640 | MDU6SXNzdWUzNjE4NTg2NDA= | 2423 | manually specify chunks in open_zarr | rabernat 1197350 | closed | 0 | 2 | 2018-09-19T17:52:31Z | 2020-01-09T15:21:35Z | 2020-01-09T15:21:35Z | MEMBER | Currently, Note that this is not the same as calling |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2423/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 396285440 | MDU6SXNzdWUzOTYyODU0NDA= | 2656 | dataset info in .json format | rabernat 1197350 | closed | 0 | 9 | 2019-01-06T19:13:34Z | 2020-01-08T22:43:25Z | 2019-01-21T23:25:56Z | MEMBER | I am exploring the world of Spatio Temporal Asset Catalogs (STAC), in which all datasets are described using json/ geojson:
I am thinking about how to put the sort of datasets that xarray deals with into STAC items (see https://github.com/radiantearth/stac-spec). This would be particular valuable in the context of Pangeo and the zarr-based datasets we have been putting in cloud storage. For this purpose, it would be very useful to have a concise summary of an xarray dataset's contents (minus the actual data) in .json format. I'm talking about the kind of info we currently get from the For example
variables: float64 foo(x) ; foo:units = m s-1 ; int64 x(x) ; x:units = m ; // global attributes: :conventions = made up ; ``` I would like to be able to do Which is what I get by doing If anyone is aware of an existing spec for expressing Common Data Language in json, we should probably use that instead of inventing our own. But I think some version of this would be a very useful addition to xarray. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2656/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 288785270 | MDU6SXNzdWUyODg3ODUyNzA= | 1832 | groupby on dask objects doesn't handle chunks well | rabernat 1197350 | closed | 0 | 22 | 2018-01-16T04:50:22Z | 2019-11-27T16:45:14Z | 2019-06-06T20:01:40Z | MEMBER | 80% of climate data analysis begins with calculating the monthly-mean climatology and subtracting it from the dataset to get an anomaly. Unfortunately this is a fail case for xarray / dask with out-of-core datasets. This is becoming a serious problem for me. Code Sample```python Your code hereimport xarray as xr import dask.array as da import pandas as pd construct an example datatset chunked in timent, ny, nx = 366, 180, 360 time = pd.date_range(start='1950-01-01', periods=nt, freq='10D') ds = xr.DataArray(da.random.random((nt, ny, nx), chunks=(1, ny, nx)), dims=('time', 'lat', 'lon'), coords={'time': time}).to_dataset(name='field') monthly climatologyds_mm = ds.groupby('time.month').mean(dim='time') anomalyds_anom = ds.groupby('time.month')- ds_mm
print(ds_anom)
Problem descriptionAs we can see in the example above, the chunking has been lost. The dataset contains just one single huge chunk. This happens with any non-reducing operation on the groupby, even
Say we wanted to compute some statistics of the anomaly, like the variance:
Expected OutputIt seems like we should be able to do this lazily, maintaining a chunk size of Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1832/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 467776251 | MDExOlB1bGxSZXF1ZXN0Mjk3MzU0NTEx | 3121 | Allow other tutorial filename extensions | rabernat 1197350 | closed | 0 | 3 | 2019-07-13T23:27:44Z | 2019-07-14T01:07:55Z | 2019-07-14T01:07:51Z | MEMBER | 0 | pydata/xarray/pulls/3121 |
Together with https://github.com/pydata/xarray-data/pull/15, this allows us to generalize out tutorial datasets to non netCDF files. But it is backwards compatible--if there is no file suffix, it will append |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3121/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 467674875 | MDExOlB1bGxSZXF1ZXN0Mjk3MjgyNzA1 | 3106 | Replace sphinx_gallery with notebook | rabernat 1197350 | closed | 0 | 3 | 2019-07-13T05:35:34Z | 2019-07-13T14:03:20Z | 2019-07-13T14:03:19Z | MEMBER | 0 | pydata/xarray/pulls/3106 | Today @jhamman and I discussed how to refactor our somewhat fragmented "examples". We decided to basically copy the approach of the dask-examples repo, but have it live here in the main xarray repo. Basically this approach is: - all examples are notebooks - examples are rendered during doc build by nbsphinx - we will eventually have a binder that works with all of the same examples This PR removes the dependency on sphinx_gallery and replaces the existing gallery with a standalone notebook called Really important to get @dcherian's feedback on this, as he was the one who originally introduced the gallery. My view is that having everything as notebooks makes examples easier to maintain. But I'm curious to hear other views. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 467658326 | MDExOlB1bGxSZXF1ZXN0Mjk3MjcwNjYw | 3105 | Switch doc examples to use nbsphinx | rabernat 1197350 | closed | 0 | 4 | 2019-07-13T02:28:34Z | 2019-07-13T04:53:09Z | 2019-07-13T04:52:52Z | MEMBER | 0 | pydata/xarray/pulls/3105 | This is the beginning of the docs refactor we have in mind for the sprint tomorrow. We will merge things first to the scipy19-docs branch so we can make sure things build on RTD. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3105/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 218260909 | MDU6SXNzdWUyMTgyNjA5MDk= | 1340 | round-trip performance with save_mfdataset / open_mfdataset | rabernat 1197350 | closed | 0 | 11 | 2017-03-30T16:52:26Z | 2019-05-01T22:12:06Z | 2019-05-01T22:12:06Z | MEMBER | I have encountered some major performance bottlenecks in trying to write and then read multi-file netcdf datasets. I start with an xarray dataset created by xgcm with the following repr:
An important point to note is that there are lots of "non-dimension coordinates" corresponding to various parameters of the numerical grid. I save this dataset to a multi-file netCDF dataset as follows:
Then I try to re-load this dataset
This raises an error:
I need to specify I just thought I would document this, because 18 minutes seems way too long to load a dataset. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1340/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 431199282 | MDExOlB1bGxSZXF1ZXN0MjY4OTI3MjU0 | 2881 | decreased pytest verbosity | rabernat 1197350 | closed | 0 | 1 | 2019-04-09T21:12:50Z | 2019-04-09T23:36:01Z | 2019-04-09T23:34:22Z | MEMBER | 0 | pydata/xarray/pulls/2881 | This removes the
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2881/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 431156227 | MDU6SXNzdWU0MzExNTYyMjc= | 2880 | pytest output on travis is too verbose | rabernat 1197350 | closed | 0 | 1 | 2019-04-09T19:39:46Z | 2019-04-09T23:34:22Z | 2019-04-09T23:34:22Z | MEMBER | I have to scroll over an immense amount of passing tests on travis before I can get to the failures. (example) This is pretty annoying. The amount of tests in xarray has exploded recently. This is good! But maybe we should turn off What does @pydata/xarray think? |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2880/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 373121666 | MDU6SXNzdWUzNzMxMjE2NjY= | 2503 | Problems with distributed and opendap netCDF endpoint | rabernat 1197350 | closed | 0 | 26 | 2018-10-23T17:48:20Z | 2019-04-09T12:02:01Z | 2019-04-09T12:02:01Z | MEMBER | Code SampleI am trying to load a dataset from an opendap endpoint using xarray, netCDF4, and distributed. I am having a problem only with non-local distributed schedulers (KubeCluster specifically). This could plausibly be an xarray, dask, or pangeo issue, but I have decided to post it here. ```python import xarray as xr import dask create dataset from Unidata's test opendap endpoint, chunked in timeurl = 'http://remotetest.unidata.ucar.edu/thredds/dodsC/testdods/coads_climatology.nc' ds = xr.open_dataset(url, decode_times=False, chunks={'TIME': 1}) all these workwith dask.config.set(scheduler='synchronous'): ds.SST.compute() with dask.config.set(scheduler='processes'): ds.SST.compute() with dask.config.set(scheduler='threads'): ds.SST.compute() this works toofrom dask.distributed import Client local_client = Client() with dask.config.set(get=local_client): ds.SST.compute() but this does notcluster = KubeCluster(n_workers=2) kube_client = Client(cluster) with dask.config.set(get=kube_client): ds.SST.compute() ``` In the worker log, I see the following sort of errors.
This seems like something to do with serialization of the netCDF store. The worker images have identical netcdf version (and all other package versions). I am at a loss for how to debug further. Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2503/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 209561985 | MDU6SXNzdWUyMDk1NjE5ODU= | 1282 | description of xarray assumes knowledge of pandas | rabernat 1197350 | closed | 0 | 4 | 2017-02-22T19:52:54Z | 2019-02-26T19:01:47Z | 2019-02-26T19:01:46Z | MEMBER | The first sentence a potential new user reads about xarray is
Now imagine you had never heard of pandas (like most new Ph.D. students in physical sciences). You would have no idea how useful and powerful xarray was. I would propose modifying these top-level descriptions to remove the assumption that the user understands pandas. Of course we can still refer to pandas, but a more self-contained description would serve us well. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1282/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 396501063 | MDExOlB1bGxSZXF1ZXN0MjQyNjY4ODEw | 2659 | to_dict without data | rabernat 1197350 | closed | 0 | 14 | 2019-01-07T14:09:25Z | 2019-02-12T21:21:13Z | 2019-01-21T23:25:56Z | MEMBER | 0 | pydata/xarray/pulls/2659 | This PR provides the ability to export Datasets and DataArrays to dictionary without the actual data. This could be useful for generating indices of dataset contents to expose to search indices or other automated data discovery tools In the process of doing this, I refactored the core dictionary export function to live in the Variable class, since the same code was duplicated in several places.
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 324740017 | MDU6SXNzdWUzMjQ3NDAwMTc= | 2164 | holoviews / bokeh doesn't like cftime coords | rabernat 1197350 | closed | 0 | 16 | 2018-05-20T20:29:03Z | 2019-02-08T00:11:14Z | 2019-02-08T00:11:14Z | MEMBER | Code Sample, a copy-pastable example if possibleConsider a simple working example of converting an xarray dataset to holoviews for plotting:
This gives
Problem descriptionNow change but holoviews / bokeh doesn't like it ``` /opt/conda/lib/python3.6/site-packages/xarray/coding/times.py:132: SerializationWarning: Unable to decode time axis into full numpy.datetime64 objects, continuing using dummy cftime.datetime objects instead, reason: dates out of range enable_cftimeindex) /opt/conda/lib/python3.6/site-packages/xarray/coding/variables.py:66: SerializationWarning: Unable to decode time axis into full numpy.datetime64 objects, continuing using dummy cftime.datetime objects instead, reason: dates out of range return self.func(self.array[key]) TypeError Traceback (most recent call last) /opt/conda/lib/python3.6/site-packages/IPython/core/formatters.py in call(self, obj, include, exclude) 968 969 if method is not None: --> 970 return method(include=include, exclude=exclude) 971 return None 972 else: /opt/conda/lib/python3.6/site-packages/holoviews/core/dimension.py in repr_mimebundle(self, include, exclude) 1229 combined and returned. 1230 """ -> 1231 return Store.render(self) 1232 1233 /opt/conda/lib/python3.6/site-packages/holoviews/core/options.py in render(cls, obj) 1287 data, metadata = {}, {} 1288 for hook in hooks: -> 1289 ret = hook(obj) 1290 if ret is None: 1291 continue /opt/conda/lib/python3.6/site-packages/holoviews/ipython/display_hooks.py in pprint_display(obj) 278 if not ip.display_formatter.formatters['text/plain'].pprint: 279 return None --> 280 return display(obj, raw_output=True) 281 282 /opt/conda/lib/python3.6/site-packages/holoviews/ipython/display_hooks.py in display(obj, raw_output, **kwargs) 248 elif isinstance(obj, (CompositeOverlay, ViewableElement)): 249 with option_state(obj): --> 250 output = element_display(obj) 251 elif isinstance(obj, (Layout, NdLayout, AdjointLayout)): 252 with option_state(obj): /opt/conda/lib/python3.6/site-packages/holoviews/ipython/display_hooks.py in wrapped(element) 140 try: 141 max_frames = OutputSettings.options['max_frames'] --> 142 mimebundle = fn(element, max_frames=max_frames) 143 if mimebundle is None: 144 return {}, {} /opt/conda/lib/python3.6/site-packages/holoviews/ipython/display_hooks.py in element_display(element, max_frames) 186 return None 187 --> 188 return render(element) 189 190 /opt/conda/lib/python3.6/site-packages/holoviews/ipython/display_hooks.py in render(obj, kwargs) 63 renderer = renderer.instance(fig='png') 64 ---> 65 return renderer.components(obj, kwargs) 66 67 /opt/conda/lib/python3.6/site-packages/holoviews/plotting/bokeh/renderer.py in components(self, obj, fmt, comm, kwargs) 257 # Bokeh has to handle comms directly in <0.12.15 258 comm = False if bokeh_version < '0.12.15' else comm --> 259 return super(BokehRenderer, self).components(obj,fmt, comm, kwargs) 260 261 /opt/conda/lib/python3.6/site-packages/holoviews/plotting/renderer.py in components(self, obj, fmt, comm, **kwargs) 319 plot = obj 320 else: --> 321 plot, fmt = self._validate(obj, fmt) 322 323 widget_id = None /opt/conda/lib/python3.6/site-packages/holoviews/plotting/renderer.py in _validate(self, obj, fmt, kwargs) 218 if isinstance(obj, tuple(self.widgets.values())): 219 return obj, 'html' --> 220 plot = self.get_plot(obj, renderer=self, kwargs) 221 222 fig_formats = self.mode_formats['fig'][self.mode] /opt/conda/lib/python3.6/site-packages/holoviews/plotting/bokeh/renderer.py in get_plot(self_or_cls, obj, doc, renderer) 150 doc = Document() if self_or_cls.notebook_context else curdoc() 151 doc.theme = self_or_cls.theme --> 152 plot = super(BokehRenderer, self_or_cls).get_plot(obj, renderer) 153 plot.document = doc 154 return plot /opt/conda/lib/python3.6/site-packages/holoviews/plotting/renderer.py in get_plot(self_or_cls, obj, renderer) 205 init_key = tuple(v if d is None else d for v, d in 206 zip(plot.keys[0], defaults)) --> 207 plot.update(init_key) 208 else: 209 plot = obj /opt/conda/lib/python3.6/site-packages/holoviews/plotting/plot.py in update(self, key) 511 def update(self, key): 512 if len(self) == 1 and ((key == 0) or (key == self.keys[0])) and not self.drawn: --> 513 return self.initialize_plot() 514 item = self.getitem(key) 515 self.traverse(lambda x: setattr(x, '_updated', True)) /opt/conda/lib/python3.6/site-packages/holoviews/plotting/bokeh/element.py in initialize_plot(self, ranges, plot, plots, source) 729 if not self.overlaid: 730 self._update_plot(key, plot, style_element) --> 731 self._update_ranges(style_element, ranges) 732 733 for cb in self.callbacks: /opt/conda/lib/python3.6/site-packages/holoviews/plotting/bokeh/element.py in _update_ranges(self, element, ranges) 498 if not self.drawn or xupdate: 499 self._update_range(x_range, l, r, xfactors, self.invert_xaxis, --> 500 self._shared['x'], self.logx, streaming) 501 if not self.drawn or yupdate: 502 self._update_range(y_range, b, t, yfactors, self.invert_yaxis, /opt/conda/lib/python3.6/site-packages/holoviews/plotting/bokeh/element.py in _update_range(self, axis_range, low, high, factors, invert, shared, log, streaming) 525 updates = {} 526 if low is not None and (isinstance(low, util.datetime_types) --> 527 or np.isfinite(low)): 528 updates['start'] = (axis_range.start, low) 529 if high is not None and (isinstance(high, util.datetime_types) TypeError: ufunc 'isfinite' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe'' ``` Similar but slightly different errors arise for different holoviews types (e.g. Expected OutputThis should work. I'm not sure if this is really an xarray problem. Maybe it needs a fix in holoviews (or bokeh). But I'm raising it here first since clearly we have introduced this new wrinkle in the stack. Cc'ing @philippjfr since he is the expert on all things holoviews. Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2164/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 193657418 | MDU6SXNzdWUxOTM2NTc0MTg= | 1154 | netCDF reading is not prominent in the docs | rabernat 1197350 | closed | 0 | 7 | 2016-12-06T01:18:40Z | 2019-02-02T06:33:44Z | 2019-02-02T06:33:44Z | MEMBER | Just opening an issue to highlight what I think is a problem with the docs. For me, the primary use of xarray is to read and process existing netCDF data files. @shoyer's popular blog post illustrates this use case extremely well. However, when I open the docs, I have to dig quite deep before I can see how to read a netCDF file. This could be turning away many potential users. The stuff about netCDF reading is hidden under "Serialization and IO". Many potential users will have no idea what either of these words mean. IMO the solution to this is to reorganize the docs to make reading netCDF much more prominent and obvious. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1154/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 225734529 | MDU6SXNzdWUyMjU3MzQ1Mjk= | 1394 | autoclose with distributed doesn't seem to work | rabernat 1197350 | closed | 0 | 9 | 2017-05-02T15:37:07Z | 2019-01-13T19:35:10Z | 2019-01-13T19:35:10Z | MEMBER | I am trying to analyze a very large netCDF dataset using xarray and distributed. I open my dataset with the new However, when I try some reduction operation (e.g. Am I doing something wrong here? Why are the files not being closed? cc: @pwolfram |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1394/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 225774140 | MDU6SXNzdWUyMjU3NzQxNDA= | 1396 | selecting a point from an mfdataset | rabernat 1197350 | closed | 0 | 12 | 2017-05-02T18:02:50Z | 2019-01-13T06:32:45Z | 2019-01-13T06:32:45Z | MEMBER | Sorry to be opening so many vague performance issues. I am really having a hard time with my current dataset, which is exposing certain limitations of xarray and dask in a way none of my previous work has done. I have a directory full of netCDF4 files. There are 1754 files, each 8.1GB in size, each representing a single model timestep. So there is ~14 TB of data total. (In addition to the time-dependent output, there is a single file with information about the grid.) Imagine I want to extract a timeseries from a single point (indexed by I could do the same sort of loop using xarray:
Of course, what I really want is to avoid a loop and deal with the whole dataset as a single self-contained object.
Now, to extract the same timeseries, I would like to say
I monitor what is happening under the hood using when I call this by using netdata and the dask.distributed dashboard, using only a single process and thread. First, all the files are opened (see #1394). Then they start getting read. Each read takes between 10 and 30 seconds, and the memory usage starts increasing steadily. My impression is that the entire dataset is being read into memory for concatenation. (I have dumped out the dask graph in case anyone can make sense of it.) I have never let this calculation complete, as it looks like it would eat up all the memory on my system...plus it's extremely slow. To me, this seems like a failure of lazy indexing. I naively expected that the underlying file access would work similar to my loop, perhaps even in parallel. Can anyone shed some light on what might be going wrong? |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1396/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 108623921 | MDU6SXNzdWUxMDg2MjM5MjE= | 591 | distarray backend? | rabernat 1197350 | closed | 0 | 5 | 2015-09-28T09:49:52Z | 2019-01-13T04:11:08Z | 2019-01-13T04:11:08Z | MEMBER | This is probably a long shot, but I think a distarray backend could potentially be very useful in xray. Distarray implements the numpy interface, so it should be possible in principle. Distarray has a different architecture from dask (using MPI for parallelization) and in this way is more similar to traditional HPC codes. The application I have in mind is very high resolution GCM output where one wants to tile the data spatially across multiple nodes on a cluster. (This is how a GCM itself works.) |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 280626621 | MDU6SXNzdWUyODA2MjY2MjE= | 1770 | slow performance when storing datasets in gcsfs-backed zarr stores | rabernat 1197350 | closed | 0 | 11 | 2017-12-08T21:46:32Z | 2019-01-13T03:52:46Z | 2019-01-13T03:52:46Z | MEMBER | We are working on integrating zarr with xarray. In the process, we have encountered a performance issue that I am documenting here. At this point, it is not clear if the core issue is in zarr, gcsfs, dask, or xarray. I originally started posting this in zarr, but in the process, I became more convinced the issue was with xarray. Dask OnlyHere is an example using only dask and zarr. ```python connect to a local dask schedulerfrom dask.distributed import Client client = Client('tcp://129.236.20.45:8786') create a big dask arrayimport dask.array as dsa shape = (30, 50, 1080, 2160) chunkshape = (1, 1, 1080, 2160) ar = dsa.random.random(shape, chunks=chunkshape) connect to gcs and create MutableMappingimport gcsfs fs = gcsfs.GCSFileSystem(project='pangeo-181919') gcsmap = gcsfs.mapping.GCSMap('pangeo-data/test999', gcs=fs, check=True, create=True) create a zarr array to store intoimport zarr za = zarr.create(ar.shape, chunks=chunkshape, dtype=ar.dtype, store=gcsmap) write itar.store(za, lock=False) ``` When you do this, it spends a long time serializing stuff before the computation starts. For a more fine-grained look at the process, one can instead do
Some debugging by @mrocklin revealed the following step is quite slow
There is room for improvement here, but overall, zarr + gcsfs + dask seem to integrate well and give decent performance. XarrayThis get much worse once xarray enters the picture. (Note that this example requires the xarray PR pydata/xarray#1528, which has not been merged yet.) ```python wrap the dask array in an xarrayimport xarray as xr import numpy as np ds = xr.DataArray(ar, dims=['time', 'depth', 'lat', 'lon'], coords={'lat': np.linspace(-90, 90, Ny), 'lon': np.linspace(0, 360, Nx)}).to_dataset(name='temperature') store to a different bucketgcsmap = gcsfs.mapping.GCSMap('pangeo-data/test1', gcs=fs, check=True, create=True) ds.to_zarr(store=gcsmap, mode='w') ``` Now the store step takes 18 minutes. Most of this time, is upfront, during which there is little CPU activity and no network activity. After about 15 minutes or so, it finally starts computing, at which point the writes to gcs proceed more-or-less at the same rate as with the dask-only example. Profiling the
I don't understand this, since I specifically eliminated locks when storing the zarr arrays. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1770/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 362866468 | MDExOlB1bGxSZXF1ZXN0MjE3NDYzMTU4 | 2430 | WIP: revise top-level package description | rabernat 1197350 | closed | 0 | 10 | 2018-09-22T15:35:47Z | 2019-01-07T01:04:19Z | 2019-01-06T00:31:57Z | MEMBER | 0 | pydata/xarray/pulls/2430 | I have often complained that xarray's top-level package description assumes that the user knows all about pandas. I think this alienates many new users. This is a first draft at revising that top-level description. Feedback from the community very needed here. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2430/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 389594572 | MDU6SXNzdWUzODk1OTQ1NzI= | 2597 | add dayofyear to CFTimeIndex | rabernat 1197350 | closed | 0 | 2 | 2018-12-11T04:41:59Z | 2018-12-11T19:28:31Z | 2018-12-11T19:28:31Z | MEMBER | I have noticed that Perhaps there are other similar attributes. I don't know if |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2597/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 382497709 | MDExOlB1bGxSZXF1ZXN0MjMyMTkwMjg5 | 2559 | Zarr consolidated | rabernat 1197350 | closed | 0 | 19 | 2018-11-20T04:39:41Z | 2018-12-05T14:58:58Z | 2018-12-04T23:51:00Z | MEMBER | 0 | pydata/xarray/pulls/2559 | This PR adds support for reading and writing of consolidated metadata in zarr stores.
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2559/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 382043672 | MDU6SXNzdWUzODIwNDM2NzI= | 2558 | how to incorporate zarr's new open_consolidated method? | rabernat 1197350 | closed | 0 | 1 | 2018-11-19T03:28:40Z | 2018-12-04T23:51:00Z | 2018-12-04T23:51:00Z | MEMBER | Zarr has a new feature called consolidated metadata. This feature will make it much faster to open certain zarr datasets, because all the metadata needed to construct the xarray dataset will live in a single .json file. To use this new feature, the new function I am seeking feedback on what API people would like to see before starting a PR. My proposal is to add a new keyword argument to I played around with this a bit and realized that https://github.com/zarr-developers/zarr/issues/336 needs to be resolved before we can do the xarray side. cc @martindurant, who might want to weigh on what would be most convenient for intake. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2558/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 301891754 | MDU6SXNzdWUzMDE4OTE3NTQ= | 1955 | Skipping / failing zarr tests | rabernat 1197350 | closed | 0 | 3 | 2018-03-02T20:17:31Z | 2018-10-29T00:25:34Z | 2018-10-29T00:25:34Z | MEMBER | Zarr tests are currently getting skipped on our main testing environments (because the zarr version is less than 2.2): https://travis-ci.org/pydata/xarray/jobs/348350073#L1264 And failing in the I'm not sure how this regression occurred, but the zarr tests have been failing for a long time, e.g. https://travis-ci.org/pydata/xarray/jobs/342651302 Possibly related to #1954 cc @jhamman |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1955/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 332762756 | MDU6SXNzdWUzMzI3NjI3NTY= | 2234 | fillna error with distributed | rabernat 1197350 | closed | 0 | 3 | 2018-06-15T12:54:54Z | 2018-06-15T13:13:54Z | 2018-06-15T13:13:54Z | MEMBER | Code Sample, a copy-pastable example if possibleThe following code works with the default dask threaded scheduler.
It fails with distributed. I see the following error on the client side: ``` KilledWorker Traceback (most recent call last) <ipython-input-7-5ed3c292af2e> in <module>() ----> 1 da.fillna(0.).mean().load() /opt/conda/lib/python3.6/site-packages/xarray/core/dataarray.py in load(self, kwargs) 631 dask.array.compute 632 """ --> 633 ds = self._to_temp_dataset().load(kwargs) 634 new = self._from_temp_dataset(ds) 635 self._variable = new._variable /opt/conda/lib/python3.6/site-packages/xarray/core/dataset.py in load(self, kwargs) 489 490 # evaluate all the dask arrays simultaneously --> 491 evaluated_data = da.compute(*lazy_data.values(), kwargs) 492 493 for k, data in zip(lazy_data, evaluated_data): /opt/conda/lib/python3.6/site-packages/dask/base.py in compute(args, kwargs) 398 keys = [x.dask_keys() for x in collections] 399 postcomputes = [x.dask_postcompute() for x in collections] --> 400 results = schedule(dsk, keys, kwargs) 401 return repack([f(r, a) for r, (f, a) in zip(results, postcomputes)]) 402 /opt/conda/lib/python3.6/site-packages/distributed/client.py in get(self, dsk, keys, restrictions, loose_restrictions, resources, sync, asynchronous, direct, retries, priority, fifo_timeout, **kwargs) 2157 try: 2158 results = self.gather(packed, asynchronous=asynchronous, -> 2159 direct=direct) 2160 finally: 2161 for f in futures.values(): /opt/conda/lib/python3.6/site-packages/distributed/client.py in gather(self, futures, errors, maxsize, direct, asynchronous) 1560 return self.sync(self._gather, futures, errors=errors, 1561 direct=direct, local_worker=local_worker, -> 1562 asynchronous=asynchronous) 1563 1564 @gen.coroutine /opt/conda/lib/python3.6/site-packages/distributed/client.py in sync(self, func, args, kwargs) 650 return future 651 else: --> 652 return sync(self.loop, func, args, **kwargs) 653 654 def repr(self): /opt/conda/lib/python3.6/site-packages/distributed/utils.py in sync(loop, func, args, kwargs) 273 e.wait(10) 274 if error[0]: --> 275 six.reraise(error[0]) 276 else: 277 return result[0] /opt/conda/lib/python3.6/site-packages/six.py in reraise(tp, value, tb) 691 if value.traceback is not tb: 692 raise value.with_traceback(tb) --> 693 raise value 694 finally: 695 value = None /opt/conda/lib/python3.6/site-packages/distributed/utils.py in f() 258 yield gen.moment 259 thread_state.asynchronous = True --> 260 result[0] = yield make_coro() 261 except Exception as exc: 262 error[0] = sys.exc_info() /opt/conda/lib/python3.6/site-packages/tornado/gen.py in run(self) 1097 1098 try: -> 1099 value = future.result() 1100 except Exception: 1101 self.had_exception = True /opt/conda/lib/python3.6/site-packages/tornado/gen.py in run(self) 1105 if exc_info is not None: 1106 try: -> 1107 yielded = self.gen.throw(*exc_info) 1108 finally: 1109 # Break up a reference to itself /opt/conda/lib/python3.6/site-packages/distributed/client.py in _gather(self, futures, errors, direct, local_worker) 1437 six.reraise(type(exception), 1438 exception, -> 1439 traceback) 1440 if errors == 'skip': 1441 bad_keys.add(key) /opt/conda/lib/python3.6/site-packages/six.py in reraise(tp, value, tb) 691 if value.traceback is not tb: 692 raise value.with_traceback(tb) --> 693 raise value 694 finally: 695 value = None KilledWorker: ("('isna-mean_chunk-where-mean_agg-aggregate-74ec0f30171c1c667640f1f18df5f84b',)", 'tcp://10.20.197.7:43357')
This could very well be a distributed issue. Or a pandas issue. I'm not too sure what is going on. Why is pandas even involved at all? Problem descriptionThis should not raise an error. It worked fine in previous versions, but something in our latest environment has caused it to break. Expected Output
Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2234/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 323359733 | MDU6SXNzdWUzMjMzNTk3MzM= | 2135 | use CF conventions to enhance plot labels | rabernat 1197350 | closed | 0 | 4 | 2018-05-15T19:53:51Z | 2018-06-02T00:10:26Z | 2018-06-02T00:10:26Z | MEMBER | Elsewhere in xarray we use CF conventions to help with automatic decoding of datasets. Here I propose we consider using CF metadata conventions to improve the automatic labelling of plots. If datasets declare Code Sample, a copy-pastable example if possibleHere I create some data with relevant attributes
Problem descriptionWe have neglected the variable attributes, which would provide better axis labels. Expected OutputConsider this instead:
I feel like this would be a sensible default. But it would be a breaking change. We could make it optional with a keyword like Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2135/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 180516114 | MDU6SXNzdWUxODA1MTYxMTQ= | 1026 | multidim groupby on dask arrays: dask.array.reshape error | rabernat 1197350 | closed | 0 | 17 | 2016-10-02T14:55:25Z | 2018-05-24T17:59:31Z | 2018-05-24T17:59:31Z | MEMBER | If I try to run a groupby operation using a multidimensional group, I get an error from dask about "dask.array.reshape requires that reshaped dimensions after the first contain at most one chunk". This error is arises with dask 0.11.0 but NOT dask 0.8.0. Consider the following test example: ``` python import dask.array as da import xarray as xr nz, ny, nx = (10,20,30) data = da.ones((nz,ny,nx), chunks=(5,ny,nx)) coord_2d = da.random.random((ny,nx), chunks=(ny,nx))>0.5 ds = xr.Dataset({'thedata': (('z','y','x'), data)}, coords={'thegroup': (('y','x'), coord_2d)}) this works fineds.thedata.groupby('thegroup') ``` Now I rechunk one of the later dimensions and group again:
This raises the following error and stack trace ``` ValueError Traceback (most recent call last) <ipython-input-16-1b0095ee24a0> in <module>() ----> 1 ds.chunk({'x': 5}).thedata.groupby('thegroup') /Users/rpa/RND/open_source/xray/xarray/core/common.pyc in groupby(self, group, squeeze) 343 if isinstance(group, basestring): 344 group = self[group] --> 345 return self.groupby_cls(self, group, squeeze=squeeze) 346 347 def groupby_bins(self, group, bins, right=True, labels=None, precision=3, /Users/rpa/RND/open_source/xray/xarray/core/groupby.pyc in init(self, obj, group, squeeze, grouper, bins, cut_kwargs) 170 # the copy is necessary here, otherwise read only array raises error 171 # in pandas: https://github.com/pydata/pandas/issues/12813> --> 172 group = group.stack({stacked_dim_name: orig_dims}).copy() 173 obj = obj.stack({stacked_dim_name: orig_dims}) 174 self._stacked_dim = stacked_dim_name /Users/rpa/RND/open_source/xray/xarray/core/dataarray.pyc in stack(self, dimensions) 857 DataArray.unstack 858 """ --> 859 ds = self._to_temp_dataset().stack(dimensions) 860 return self._from_temp_dataset(ds) 861 /Users/rpa/RND/open_source/xray/xarray/core/dataset.pyc in stack(self, **dimensions) 1359 result = self 1360 for new_dim, dims in dimensions.items(): -> 1361 result = result._stack_once(dims, new_dim) 1362 return result 1363 /Users/rpa/RND/open_source/xray/xarray/core/dataset.pyc in _stack_once(self, dims, new_dim) 1322 shape = [self.dims[d] for d in vdims] 1323 exp_var = var.expand_dims(vdims, shape) -> 1324 stacked_var = exp_var.stack(**{new_dim: dims}) 1325 variables[name] = stacked_var 1326 else: /Users/rpa/RND/open_source/xray/xarray/core/variable.pyc in stack(self, **dimensions) 801 result = self 802 for new_dim, dims in dimensions.items(): --> 803 result = result._stack_once(dims, new_dim) 804 return result 805 /Users/rpa/RND/open_source/xray/xarray/core/variable.pyc in _stack_once(self, dims, new_dim) 771 772 new_shape = reordered.shape[:len(other_dims)] + (-1,) --> 773 new_data = reordered.data.reshape(new_shape) 774 new_dims = reordered.dims[:len(other_dims)] + (new_dim,) 775 /Users/rpa/anaconda/lib/python2.7/site-packages/dask/array/core.pyc in reshape(self, *shape) 1101 if len(shape) == 1 and not isinstance(shape[0], Number): 1102 shape = shape[0] -> 1103 return reshape(self, shape) 1104 1105 @wraps(topk) /Users/rpa/anaconda/lib/python2.7/site-packages/dask/array/core.pyc in reshape(array, shape) 2585 2586 if any(len(c) != 1 for c in array.chunks[ndim_same+1:]): -> 2587 raise ValueError('dask.array.reshape requires that reshaped ' 2588 'dimensions after the first contain at most one chunk') 2589 ValueError: dask.array.reshape requires that reshaped dimensions after the first contain at most one chunk ``` I am using the latest xarray master and dask version 0.11.0. Note that the example works fine if I use an earlier version of dask (e.g. 0.8.0, the only other one I tested.) This suggests an upstream issue with dask, but I wanted to bring it up here first. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1026/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 317783678 | MDU6SXNzdWUzMTc3ODM2Nzg= | 2082 | searching is broken on readthedocs | rabernat 1197350 | closed | 0 | 2 | 2018-04-25T20:34:13Z | 2018-05-04T20:10:31Z | 2018-05-04T20:10:31Z | MEMBER | Searches return no results for me. For example: http://xarray.pydata.org/en/latest/search.html?q=xarray&check_keywords=yes&area=default |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2082/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 312986662 | MDExOlB1bGxSZXF1ZXN0MTgwNjUwMjc5 | 2047 | Fix decode cf with dask | rabernat 1197350 | closed | 0 | 1 | 2018-04-10T15:56:20Z | 2018-04-12T23:38:02Z | 2018-04-12T23:38:02Z | MEMBER | 0 | pydata/xarray/pulls/2047 |
This was a very simple fix for an issue that has vexed me for quite a while. Am I missing something obvious here? |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2047/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 293913247 | MDU6SXNzdWUyOTM5MTMyNDc= | 1882 | xarray tutorial at SciPy 2018? | rabernat 1197350 | closed | 0 | 17 | 2018-02-02T14:52:11Z | 2018-04-09T20:30:13Z | 2018-04-09T20:30:13Z | MEMBER | It would be great to hold an xarray tutorial at SciPy 2018. Xarray has matured a lot recently, and it would be great to raise awareness of what it can do among the broader scipy community. From the conference website:
I'm curious if anyone was already planning on submitting a tutorial. If not, let's put together a team. @jhamman has indicated interest in participating in, but not leading, the tutorial. Anyone else interested? xref pangeo-data/pangeo#97 |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1882/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 106562046 | MDU6SXNzdWUxMDY1NjIwNDY= | 575 | 1D line plot with data on the x axis | rabernat 1197350 | closed | 0 | 13 | 2015-09-15T13:56:51Z | 2018-03-05T22:14:46Z | 2018-03-05T22:14:46Z | MEMBER | Consider the following Dataset, representing a function f = cos(z)
If I call
xray naturally puts "z" on the x-axis. However, since z represents the vertical dimension, it would be more natural do put it on the y-axis, i.e.
This is conventional in atmospheric science and oceanography for buoy data or balloon data. Is there an easy way to do this with xray's plotting functions? I scanned the code and didn't see an obvious solution, but maybe I missed it. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/575/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 295744504 | MDU6SXNzdWUyOTU3NDQ1MDQ= | 1898 | zarr RTD docs broken | rabernat 1197350 | closed | 0 | 0.10.3 3008859 | 1 | 2018-02-09T03:35:05Z | 2018-02-15T23:20:31Z | 2018-02-15T23:20:31Z | MEMBER | This is what is getting rendered on RTD http://xarray.pydata.org/en/latest/io.html#zarr ``` In [26]: ds = xr.Dataset({'foo': (('x', 'y'), np.random.rand(4, 5))}, ....: coords={'x': [10, 20, 30, 40], ....: 'y': pd.date_range('2000-01-01', periods=5), ....: 'z': ('x', list('abcd'))}) ....: In [27]: ds.to_zarr('path/to/directory.zarr')AttributeError Traceback (most recent call last) <ipython-input-27-8c5f1b00edbc> in <module>() ----> 1 ds.to_zarr('path/to/directory.zarr') /home/docs/checkouts/readthedocs.org/user_builds/xray/conda/latest/lib/python3.5/site-packages/xarray-0.10.0+dev55.g1d32399-py3.5.egg/xarray/core/dataset.py in to_zarr(self, store, mode, synchronizer, group, encoding) 1165 from ..backends.api import to_zarr 1166 return to_zarr(self, store=store, mode=mode, synchronizer=synchronizer, -> 1167 group=group, encoding=encoding) 1168 1169 def unicode(self): /home/docs/checkouts/readthedocs.org/user_builds/xray/conda/latest/lib/python3.5/site-packages/xarray-0.10.0+dev55.g1d32399-py3.5.egg/xarray/backends/api.py in to_zarr(dataset, store, mode, synchronizer, group, encoding) 752 # I think zarr stores should always be sync'd immediately 753 # TODO: figure out how to properly handle unlimited_dims --> 754 dataset.dump_to_store(store, sync=True, encoding=encoding) 755 return store /home/docs/checkouts/readthedocs.org/user_builds/xray/conda/latest/lib/python3.5/site-packages/xarray-0.10.0+dev55.g1d32399-py3.5.egg/xarray/core/dataset.py in dump_to_store(self, store, encoder, sync, encoding, unlimited_dims) 1068 1069 store.store(variables, attrs, check_encoding, -> 1070 unlimited_dims=unlimited_dims) 1071 if sync: 1072 store.sync() /home/docs/checkouts/readthedocs.org/user_builds/xray/conda/latest/lib/python3.5/site-packages/xarray-0.10.0+dev55.g1d32399-py3.5.egg/xarray/backends/zarr.py in store(self, variables, attributes, args, kwargs) 378 def store(self, variables, attributes, args, kwargs): 379 AbstractWritableDataStore.store(self, variables, attributes, --> 380 *args, kwargs) 381 382 /home/docs/checkouts/readthedocs.org/user_builds/xray/conda/latest/lib/python3.5/site-packages/xarray-0.10.0+dev55.g1d32399-py3.5.egg/xarray/backends/common.py in store(self, variables, attributes, check_encoding_set, unlimited_dims) 275 variables, attributes = self.encode(variables, attributes) 276 --> 277 self.set_attributes(attributes) 278 self.set_dimensions(variables, unlimited_dims=unlimited_dims) 279 self.set_variables(variables, check_encoding_set, /home/docs/checkouts/readthedocs.org/user_builds/xray/conda/latest/lib/python3.5/site-packages/xarray-0.10.0+dev55.g1d32399-py3.5.egg/xarray/backends/zarr.py in set_attributes(self, attributes) 341 342 def set_attributes(self, attributes): --> 343 self.ds.attrs.put(attributes) 344 345 def encode_variable(self, variable): AttributeError: 'Attributes' object has no attribute 'put' ``` |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1898/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | |||||
| 253136694 | MDExOlB1bGxSZXF1ZXN0MTM3ODE5MTA0 | 1528 | WIP: Zarr backend | rabernat 1197350 | closed | 0 | 103 | 2017-08-27T02:38:01Z | 2018-02-13T21:35:03Z | 2017-12-14T02:11:36Z | MEMBER | 0 | pydata/xarray/pulls/1528 |
I think that a zarr backend could be the ideal storage format for xarray datasets, overcoming many of the frustrations associated with netcdf and enabling optimal performance on cloud platforms. This is a very basic start to implementing a zarr backend (as proposed in #1223); however, I am taking a somewhat different approach. I store the whole dataset in a single zarr group. I encode the extra metadata needed by xarray (so far just dimension information) as attributes within the zarr group and child arrays. I hide these special attributes from the user by wrapping the attribute dictionaries in a " I have no tests yet (:flushed:), but the following code works. ```python from xarray.backends.zarr import ZarrStore import xarray as xr import numpy as np ds = xr.Dataset( {'foo': (('y', 'x'), np.ones((100, 200)), {'myattr1': 1, 'myattr2': 2}), 'bar': (('x',), np.zeros(200))}, {'y': (('y',), np.arange(100)), 'x': (('x',), np.arange(200))}, {'some_attr': 'copana'} ).chunk({'y': 50, 'x': 40}) zs = ZarrStore(store='zarr_test') ds.dump_to_store(zs) ds2 = xr.Dataset.load_store(zs) assert ds2.equals(ds) ``` There is a very long way to go here, but I thought I would just get a PR started. Some questions that would help me move forward.
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1528/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 287569331 | MDExOlB1bGxSZXF1ZXN0MTYyMjI0MTg2 | 1817 | fix rasterio chunking with s3 datasets | rabernat 1197350 | closed | 0 | 11 | 2018-01-10T20:37:45Z | 2018-01-24T09:33:07Z | 2018-01-23T16:33:28Z | MEMBER | 0 | pydata/xarray/pulls/1817 |
This is a simple fix for token generation of non-filename targets for rasterio. The problem is that I have no idea how to test it without actually hitting s3 (which requires boto and aws credentials). |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1817/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 287566823 | MDU6SXNzdWUyODc1NjY4MjM= | 1816 | rasterio chunks argument causes loading from s3 to fail | rabernat 1197350 | closed | 0 | 1 | 2018-01-10T20:28:40Z | 2018-01-23T16:33:28Z | 2018-01-23T16:33:28Z | MEMBER | Code Sample, a copy-pastable example if possible```python This worksurl = 's3://landsat-pds/L8/139/045/LC81390452014295LGN00/LC81390452014295LGN00_B1.TIF' ds = xr.open_rasterio(url) this doesn'tds = xr.open_rasterio(url, chunks=512) ``` The error is ``` FileNotFoundError Traceback (most recent call last) <ipython-input-17-8b55d7e920b8> in <module>() 6 # https://aws.amazon.com/public-datasets/landsat/ 7 # 512x512 chunking ----> 8 ds = xr.open_rasterio(url, chunks=512) 9 ds ~/miniconda3/envs/geo_scipy/lib/python3.6/site-packages/xarray-0.10.0-py3.6.egg/xarray/backends/rasterio_.py in open_rasterio(filename, chunks, cache, lock) 172 from dask.base import tokenize 173 # augment the token with the file modification time --> 174 mtime = os.path.getmtime(filename) 175 token = tokenize(filename, mtime, chunks) 176 name_prefix = 'open_rasterio-%s' % token ~/miniconda3/envs/geo_scipy/lib/python3.6/genericpath.py in getmtime(filename) 53 def getmtime(filename): 54 """Return the last modification time of a file, reported by os.stat().""" ---> 55 return os.stat(filename).st_mtime 56 57 FileNotFoundError: [Errno 2] No such file or directory: 's3://landsat-pds/L8/139/045/LC81390452014295LGN00/LC81390452014295LGN00_B1.TIF' ``` Problem descriptionIt is pretty clear that the current xarray code expects to receive a filename. (The name of the argument is Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1816/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 281983819 | MDU6SXNzdWUyODE5ODM4MTk= | 1779 | decode_cf destroys chunks | rabernat 1197350 | closed | 0 | 2 | 2017-12-14T05:12:00Z | 2017-12-15T14:50:42Z | 2017-12-15T14:50:41Z | MEMBER | Code Sample, a copy-pastable example if possible
Problem descriptionCalling
This is especially problematic if we want to concatenate several such datasets together with dask. Chunking the decoded dataset creates a nested dask-within-dask array which is sure to cause undesirable behavior down the line ```python
Expected OutputIf we call Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1779/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 94328498 | MDU6SXNzdWU5NDMyODQ5OA== | 463 | open_mfdataset too many files | rabernat 1197350 | closed | 0 | 47 | 2015-07-10T15:24:14Z | 2017-11-27T12:17:17Z | 2017-03-23T19:22:43Z | MEMBER | I am very excited to try xray. On my first attempt, I tried to use open_mfdataset on a set of ~8000 netcdf files. I hit a "RuntimeError: Too many open files". The ulimit on my system is 1024, so clearly that is the source of the error. I am curious whether this is the desired behavior for open_mfdataset. Does xray have to keep all the files open? If so, I will work with my sysadmin to increase the ulimit. It seems like the whole point of this function is to work with large collections of files, so this could be a significant limitation. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/463/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 229474101 | MDExOlB1bGxSZXF1ZXN0MTIxMTQyODkw | 1413 | concat prealigned objects | rabernat 1197350 | closed | 0 | 11 | 2017-05-17T20:16:00Z | 2017-07-17T21:53:53Z | 2017-07-17T21:53:40Z | MEMBER | 0 | pydata/xarray/pulls/1413 |
This is an initial PR to bypass index alignment and coordinate checking when concatenating datasets. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1413/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 229138906 | MDExOlB1bGxSZXF1ZXN0MTIwOTAzMjY5 | 1411 | fixed dask prefix naming | rabernat 1197350 | closed | 0 | 6 | 2017-05-16T19:10:30Z | 2017-05-22T20:39:01Z | 2017-05-22T20:38:56Z | MEMBER | 0 | pydata/xarray/pulls/1411 |
I am starting a new PR for this since the original one (#1345) was not branched of my own fork. As the discussion there stood, @shoyer suggested that ```python def maybe_chunk(name, var, chunks): chunks = selkeys(chunks, var.dims) if not chunks: chunks = None if var.ndim > 0: token2 = tokenize(name, token if token else var._data) name2 = '%s%s-%s' % (name_prefix, name, token2) return var.chunk(chunks, name=name2, lock=lock) else: return var ``` Currently, IMO, the current naming logic in |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1411/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 218368855 | MDExOlB1bGxSZXF1ZXN0MTEzNTU0Njk4 | 1345 | new dask prefix | rabernat 1197350 | closed | 0 | 2 | 2017-03-31T00:56:24Z | 2017-05-21T09:45:39Z | 2017-05-16T19:11:13Z | MEMBER | 0 | pydata/xarray/pulls/1345 |
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1345/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 225482023 | MDExOlB1bGxSZXF1ZXN0MTE4NDA4NDc1 | 1390 | Fix groupby bins tests | rabernat 1197350 | closed | 0 | 1 | 2017-05-01T17:46:41Z | 2017-05-01T21:52:14Z | 2017-05-01T21:52:14Z | MEMBER | 0 | pydata/xarray/pulls/1390 |
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1390/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 220078792 | MDU6SXNzdWUyMjAwNzg3OTI= | 1357 | dask strict version check fails | rabernat 1197350 | closed | 0 | 1 | 2017-04-07T01:08:56Z | 2017-04-07T01:43:53Z | 2017-04-07T01:43:53Z | MEMBER | I am on xarray version 0.9.1-28-g1cad803 and dask version 0.14.1+39.g964b377 (both from recent github masters). I can't save chunked data to netcdf because of a failing dask version check.
The relevant part of the stack trace is ``` /home/rpa/xarray/xarray/backends/common.pyc in sync(self) 165 import dask.array as da 166 import dask --> 167 if StrictVersion(dask.version) > StrictVersion('0.8.1'): 168 da.store(self.sources, self.targets, lock=GLOBAL_LOCK) 169 else: /home/rpa/.conda/envs/lagrangian_vorticity/lib/python2.7/distutils/version.pyc in init(self, vstring) 38 def init (self, vstring=None): 39 if vstring: ---> 40 self.parse(vstring) 41 42 def repr (self): /home/rpa/.conda/envs/lagrangian_vorticity/lib/python2.7/distutils/version.pyc in parse(self, vstring) 105 match = self.version_re.match(vstring) 106 if not match: --> 107 raise ValueError, "invalid version number '%s'" % vstring 108 109 (major, minor, patch, prerelease, prerelease_num) = \ ValueError: invalid version number '0.14.1+39.g964b377' ``` It appears that |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1357/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 188537472 | MDExOlB1bGxSZXF1ZXN0OTMxNzEyODE= | 1104 | add optimization tips | rabernat 1197350 | closed | 0 | 1 | 2016-11-10T15:26:25Z | 2016-11-10T16:49:13Z | 2016-11-10T16:49:06Z | MEMBER | 0 | pydata/xarray/pulls/1104 | This adds some dask optimization tips from the mailing list (closes #1103). |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1104/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 188517316 | MDU6SXNzdWUxODg1MTczMTY= | 1103 | add dask optimization tips to docs | rabernat 1197350 | closed | 0 | 0 | 2016-11-10T14:08:39Z | 2016-11-10T16:49:06Z | 2016-11-10T16:49:06Z | MEMBER | We should add the optimization tips that @shoyer describes in this mailing list thread to @karenamckinnon. Specific things to try (we should add similar guidelines to xarray's docs):
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 180536861 | MDExOlB1bGxSZXF1ZXN0ODc2NDc0MDk= | 1027 | Groupby bins empty groups | rabernat 1197350 | closed | 0 | 7 | 2016-10-02T21:31:32Z | 2016-10-03T15:22:18Z | 2016-10-03T15:22:15Z | MEMBER | 0 | pydata/xarray/pulls/1027 | This PR fixes a bug in Fixes #1019 |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1027/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 178359375 | MDU6SXNzdWUxNzgzNTkzNzU= | 1014 | dask tokenize error with chunking | rabernat 1197350 | closed | 0 | 1 | 2016-09-21T14:14:10Z | 2016-09-22T02:38:08Z | 2016-09-22T02:38:08Z | MEMBER | I have hit a problem with my custom xarray store: https://github.com/xgcm/xgcm/blob/master/xgcm/models/mitgcm/mds_store.py Unfortunately it is hard for me to create a re-producible example, since this error is only coming up when I try to read a large binary dataset stored on my server. Nevertheless, I am opening an issue in hopes that someone can help me. I create an xarray dataset via a custom function
This function creates a dataset object successfully and then calls Any advice would be appreciated. The relevant stack trace is ``` python /home/rpa/xgcm/xgcm/models/mitgcm/mds_store.pyc in open_mdsdataset(dirname, iters, prefix, read_grid, delta_t, ref_date, calendar, geometry, grid_vars_to_coords, swap_dims, endian, chunks, ignore_unknown_vars) 154 # do we need more fancy logic (like open_dataset), or is this enough 155 if chunks is not None: --> 156 ds = ds.chunk(chunks) 157 158 return ds /home/rpa/xarray/xarray/core/dataset.py in chunk(self, chunks, name_prefix, token, lock) 863 864 variables = OrderedDict([(k, maybe_chunk(k, v, chunks)) --> 865 for k, v in self.variables.items()]) 866 return self._replace_vars_and_dims(variables) 867 /home/rpa/xarray/xarray/core/dataset.py in maybe_chunk(name, var, chunks) 856 chunks = None 857 if var.ndim > 0: --> 858 token2 = tokenize(name, token if token else var._data) 859 name2 = '%s%s-%s' % (name_prefix, name, token2) 860 return var.chunk(chunks, name=name2, lock=lock) /home/rpa/dask/dask/base.pyc in tokenize(args, *kwargs) 355 if kwargs: 356 args = args + (kwargs,) --> 357 return md5(str(tuple(map(normalize_token, args))).encode()).hexdigest() /home/rpa/dask/dask/utils.pyc in call(self, arg) 510 for cls in inspect.getmro(typ)[1:]: 511 if cls in lk: --> 512 return lkcls 513 raise TypeError("No dispatch for {0} type".format(typ)) 514 /home/rpa/dask/dask/base.pyc in normalize_array(x) 320 return (str(x), x.dtype) 321 if hasattr(x, 'mode') and hasattr(x, 'filename'): --> 322 return x.filename, os.path.getmtime(x.filename), x.dtype, x.shape 323 if x.dtype.hasobject: 324 try: /usr/local/anaconda/lib/python2.7/genericpath.pyc in getmtime(filename) 60 def getmtime(filename): 61 """Return the last modification time of a file, reported by os.stat().""" ---> 62 return os.stat(filename).st_mtime 63 64 TypeError: coercing to Unicode: need string or buffer, NoneType found ``` |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/1014/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 146182176 | MDExOlB1bGxSZXF1ZXN0NjU0MDc4NzA= | 818 | Multidimensional groupby | rabernat 1197350 | closed | 0 | 61 | 2016-04-06T04:14:37Z | 2016-07-31T23:02:59Z | 2016-07-08T01:50:38Z | MEMBER | 0 | pydata/xarray/pulls/818 | Many datasets have a two dimensional coordinate variable (e.g. longitude) which is different from the logical grid coordinates (e.g. nx, ny). (See #605.) For plotting purposes, this is solved by #608. However, we still might want to split / apply / combine over such coordinates. That has not been possible, because groupby only supports creating groups on one-dimensional arrays. This PR overcomes that issue by using ``` python
This feature could have broad applicability for many realistic datasets (particularly model output on irregular grids): for example, averaging non-rectangular grids zonally (i.e. in latitude), binning in temperature, etc. If you think this is worth pursuing, I would love some feedback. The PR is not complete. Some items to address are
- [x] Create a specialized grouper to allow coarser bins. By default, if no |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/818/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 162974170 | MDExOlB1bGxSZXF1ZXN0NzU2ODI3NzM= | 892 | fix printing of unicode attributes | rabernat 1197350 | closed | 0 | 2 | 2016-06-29T16:47:27Z | 2016-07-24T02:57:13Z | 2016-07-24T02:57:13Z | MEMBER | 0 | pydata/xarray/pulls/892 | fixes #834 I would welcome a suggestion of how to test this in a way that works with both python 2 and 3. This is somewhat outside my expertise. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/892/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 100055216 | MDExOlB1bGxSZXF1ZXN0NDIwMTYyMDg= | 524 | Option for closing files with scipy backend | rabernat 1197350 | closed | 0 | 6 | 2015-08-10T12:49:23Z | 2016-06-24T17:45:07Z | 2016-06-24T17:45:07Z | MEMBER | 0 | pydata/xarray/pulls/524 | This is the same as #468, which was accidentally closed. I just copied and pasted my comment below This addresses issue #463, in which open_mfdataset failed when trying to open a list of files longer than my system's ulimit. I tried to find a solution in which the underlying netcdf file objects are kept closed by default and only reopened "when needed". I ended up subclassing scipy.io.netcdf_file and overwriting the variable attribute with a property which first checks whether the file is open or closed and opens it if needed. That was the easy part. The hard part was figuring out when to close them. The problem is that a couple of different parts of the code (e.g. each individual variable and also the datastore object itself) keep references to the netcdf_file object. In the end I used the debugger to find out when during initialization the variables were actually being read and added some calls to close() in various different places. It is relatively easy to close the files up at the end of the initialization, but it was much harder to make sure that the whole array of files is never open at the same time. I also had to disable mmap when this option is active. This solution is messy and, moreover, extremely slow. There is a factor of ~100 performance penalty during initialization for reopening and closing the files all the time (but only a factor of 10 for the actual calculation). I am sure this could be reduced if someone who understands the code better found some judicious points at which to call close() on the netcdf_file. The loss of mmap also sucks. This option can be accessed with the close_files key word, which I added to api. Timing for loading and doing a calculation with close_files=True:
output:
Timing for loading and doing a calculation with close_files=False (default, should revert to old behavior):
This is not a very serious pull request, but I spent all day on it, so I thought I would share. Maybe you can see some obvious way to improve it... |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/524/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 111471076 | MDU6SXNzdWUxMTE0NzEwNzY= | 624 | roll method | rabernat 1197350 | closed | 0 | 8 | 2015-10-14T19:14:36Z | 2015-12-02T23:32:28Z | 2015-12-02T23:32:28Z | MEMBER | I would like to pick up my idea to add a roll method. Among many uses, it could help with #623. The method is pretty simple.
I have already been using this function a lot (defined from outside xray) and find it quite useful. I would like to create a PR to add it, but I am having a little trouble understanding how to correctly "inject" it into the api. A few words of advice from @shoyer would probably save me a lot of trial and error. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/624/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 115897556 | MDU6SXNzdWUxMTU4OTc1NTY= | 649 | error when using broadcast_arrays with coordinates | rabernat 1197350 | closed | 0 | 5 | 2015-11-09T15:16:32Z | 2015-11-10T14:27:41Z | 2015-11-10T14:27:41Z | MEMBER | I frequently use I have found that
This raises If I change the last line to
it works fine. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/649/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 101719623 | MDExOlB1bGxSZXF1ZXN0NDI3MzE1NDg= | 538 | Fix contour color | rabernat 1197350 | closed | 0 | 25 | 2015-08-18T18:24:36Z | 2015-09-01T17:48:12Z | 2015-09-01T17:20:56Z | MEMBER | 0 | pydata/xarray/pulls/538 | This fixes #537 by adding a check for the presence of the colors kwarg. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/538/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 101716715 | MDU6SXNzdWUxMDE3MTY3MTU= | 537 | xray.plot.contour doesn't handle colors kwarg correctly | rabernat 1197350 | closed | 0 | 2 | 2015-08-18T18:11:55Z | 2015-09-01T17:20:55Z | 2015-09-01T17:20:55Z | MEMBER | I found this while playing around with the plotting functions. (Really nice work btw @clarkfitzg!) I know the plotting is still under heavy development, but I thought I would share this issue anyway. I might take a crack at fixing it myself... The goal is to make an unfilled contour plot with no colors. In matplotlib this is easy
If I try the same thing in dask
I get I can't find any way around this (e.g. adding a I think this could be fixed easily if you agree it is a bug... |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/537/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 99847237 | MDExOlB1bGxSZXF1ZXN0NDE5NjI5MDg= | 523 | Fix datetime decoding when time units are 'days since 0000-01-01 00:00:00' | rabernat 1197350 | closed | 0 | 22 | 2015-08-09T00:12:00Z | 2015-08-14T17:22:02Z | 2015-08-14T17:22:02Z | MEMBER | 0 | pydata/xarray/pulls/523 | This fixes #521 using the workaround described in Unidata/netcdf4-python#442. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/523/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 94508580 | MDExOlB1bGxSZXF1ZXN0Mzk3NTI1MTQ= | 468 | Option for closing files with scipy backend | rabernat 1197350 | closed | 0 | 7 | 2015-07-11T21:24:24Z | 2015-08-10T12:50:45Z | 2015-08-09T00:04:12Z | MEMBER | 0 | pydata/xarray/pulls/468 | This addresses issue #463, in which open_mfdataset failed when trying to open a list of files longer than my system's ulimit. I tried to find a solution in which the underlying netcdf file objects are kept closed by default and only reopened "when needed". I ended up subclassing scipy.io.netcdf_file and overwriting the variable attribute with a property which first checks whether the file is open or closed and opens it if needed. That was the easy part. The hard part was figuring out when to close them. The problem is that a couple of different parts of the code (e.g. each individual variable and also the datastore object itself) keep references to the netcdf_file object. In the end I used the debugger to find out when during initialization the variables were actually being read and added some calls to close() in various different places. It is relatively easy to close the files up at the end of the initialization, but it was much harder to make sure that the whole array of files is never open at the same time. I also had to disable mmap when this option is active. This solution is messy and, moreover, extremely slow. There is a factor of ~100 performance penalty during initialization for reopening and closing the files all the time (but only a factor of 10 for the actual calculation). I am sure this could be reduced if someone who understands the code better found some judicious points at which to call close() on the netcdf_file. The loss of mmap also sucks. This option can be accessed with the close_files key word, which I added to api. Timing for loading and doing a calculation with close_files=True:
output:
Timing for loading and doing a calculation with close_files=False (default, should revert to old behavior):
This is not a very serious pull request, but I spent all day on it, so I thought I would share. Maybe you can see some obvious way to improve it... |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/468/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 99844089 | MDExOlB1bGxSZXF1ZXN0NDE5NjI0NDM= | 522 | Fix datetime decoding when time units are 'days since 0000-01-01 00:00:00' | rabernat 1197350 | closed | 0 | 1 | 2015-08-08T23:26:07Z | 2015-08-09T00:10:18Z | 2015-08-09T00:06:49Z | MEMBER | 0 | pydata/xarray/pulls/522 | This fixes #521 using the workaround described in Unidata/netcdf4-python#442. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/522/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 96732359 | MDU6SXNzdWU5NjczMjM1OQ== | 489 | problems with big endian DataArrays | rabernat 1197350 | closed | 0 | 4 | 2015-07-23T05:24:07Z | 2015-07-23T20:28:00Z | 2015-07-23T20:28:00Z | MEMBER | I have some MITgcm data in a custom binary format that I am trying to wedge into xray. I found that DataArray does not know how to handle big endian datatypes, at least on my system.
result:
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/489/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 96185559 | MDU6SXNzdWU5NjE4NTU1OQ== | 484 | segfault with hdf4 file | rabernat 1197350 | closed | 0 | 5 | 2015-07-20T23:15:06Z | 2015-07-21T02:34:16Z | 2015-07-21T02:34:16Z | MEMBER | I am trying to read data from the NASA MERRA reanalysis. An example file is: ftp://goldsmr3.sci.gsfc.nasa.gov/data/s4pa/MERRA/MAI3CPASM.5.2.0/2014/01/MERRA300.prod.assim.inst3_3d_asm_Cp.20140101.hdf The file format is hdf4 (NOT hdf5). (full file specification) This file can be read by netCDF4.Dataset
No errors However, with xray
I get a segfault. Is this behavior unique to my system? Or is this a reproducible bug? Note: I am not using anaconda's netCDF package, because it does not have hdf4 file support. I had my sysadmin build us a custom netcdf and netCDF4 python. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/484/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue |
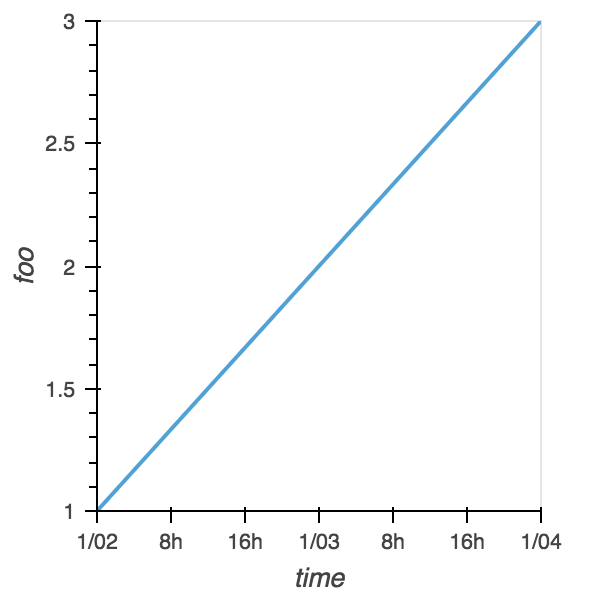



Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[active_lock_reason] TEXT,
[draft] INTEGER,
[pull_request] TEXT,
[body] TEXT,
[reactions] TEXT,
[performed_via_github_app] TEXT,
[state_reason] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);