issues
1 row where user = 89445148 sorted by updated_at descending
This data as json, CSV (advanced)
Suggested facets: created_at (date), updated_at (date), closed_at (date)
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at ▲ | closed_at | author_association | active_lock_reason | draft | pull_request | body | reactions | performed_via_github_app | state_reason | repo | type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
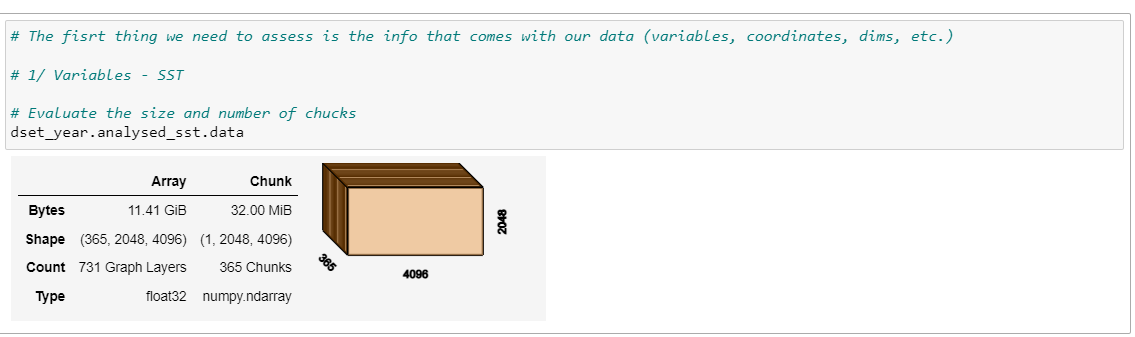
| 1441649908 | I_kwDOAMm_X85V7dT0 | 7274 | Using open_mfdataset the size of the final data becomes huge | mariasanur 89445148 | closed | 0 | 2 | 2022-11-09T08:32:07Z | 2022-11-09T09:50:40Z | 2022-11-09T09:50:39Z | NONE | What is your issue?Hi, I've been struggling with open_mfdataset because of the size of the combined final data. I have 365 files whose size in the folder was 2.2 Gb aprox., but when I open them with open_mfdataset the size becomes 11 Gb. Is there a way to avoid it?
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/7274/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue |

Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[active_lock_reason] TEXT,
[draft] INTEGER,
[pull_request] TEXT,
[body] TEXT,
[reactions] TEXT,
[performed_via_github_app] TEXT,
[state_reason] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);