issues
17 rows where user = 4711805 sorted by updated_at descending
This data as json, CSV (advanced)
Suggested facets: title, comments, closed_at, body, created_at (date), updated_at (date), closed_at (date)
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at ▲ | closed_at | author_association | active_lock_reason | draft | pull_request | body | reactions | performed_via_github_app | state_reason | repo | type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 406812274 | MDU6SXNzdWU0MDY4MTIyNzQ= | 2745 | reindex doesn't preserve chunks | davidbrochart 4711805 | open | 0 | 1 | 2019-02-05T14:37:24Z | 2023-12-04T20:46:36Z | CONTRIBUTOR | The following code creates a small (100x100) chunked ```python import xarray as xr import numpy as np n = 100 x = np.arange(n) y = np.arange(n) da = xr.DataArray(np.zeros(n*n).reshape(n, n), coords=[x, y], dims=['x', 'y']).chunk(n, n) n2 = 100000 x2 = np.arange(n2) y2 = np.arange(n2) da2 = da.reindex({'x': x2, 'y': y2}) da2 ``` But the re-indexed
Which immediately leads to a memory error when trying to e.g. store it to a
Trying to re-chunk to 100x100 before storing it doesn't help, but this time it takes a lot more time before crashing with a memory error:
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2745/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 1320562401 | I_kwDOAMm_X85Oti7h | 6844 | module 'xarray.core' has no attribute 'rolling' | davidbrochart 4711805 | closed | 0 | 2 | 2022-07-28T08:13:41Z | 2022-07-28T08:26:13Z | 2022-07-28T08:26:12Z | CONTRIBUTOR | What happened?There used to be a What did you expect to happen?Shouldn't we be able to access Minimal Complete Verifiable Example```Python import xarray as xr xr.core.rolling Traceback (most recent call last):File "<stdin>", line 1, in <module>AttributeError: module 'xarray.core' has no attribute 'rolling'``` MVCE confirmation
Relevant log outputNo response Anything else we need to know?No response Environment
/home/david/mambaforge/envs/xarray_leaflet/lib/python3.10/site-packages/_distutils_hack/__init__.py:33: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
INSTALLED VERSIONS
------------------
commit: None
python: 3.10.5 | packaged by conda-forge | (main, Jun 14 2022, 07:06:46) [GCC 10.3.0]
python-bits: 64
OS: Linux
OS-release: 5.15.0-41-generic
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: ('en_US', 'UTF-8')
libhdf5: None
libnetcdf: None
xarray: 2022.6.0
pandas: 1.4.3
numpy: 1.23.1
scipy: None
netCDF4: None
pydap: None
h5netcdf: None
h5py: None
Nio: None
zarr: None
cftime: None
nc_time_axis: None
PseudoNetCDF: None
rasterio: 1.3.0
cfgrib: None
iris: None
bottleneck: None
dask: 2022.7.1
distributed: None
matplotlib: 3.5.2
cartopy: None
seaborn: None
numbagg: None
fsspec: 2022.7.0
cupy: None
pint: None
sparse: None
flox: None
numpy_groupies: None
setuptools: 63.2.0
pip: 22.2.1
conda: None
pytest: None
IPython: 8.4.0
sphinx: None
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/6844/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 414641120 | MDU6SXNzdWU0MTQ2NDExMjA= | 2789 | Appending to zarr with string dtype | davidbrochart 4711805 | open | 0 | 2 | 2019-02-26T14:31:42Z | 2022-04-09T02:18:05Z | CONTRIBUTOR | ```python import xarray as xr da = xr.DataArray(['foo']) ds = da.to_dataset(name='da') ds.to_zarr('ds') # no special encoding specified ds = xr.open_zarr('ds') print(ds.da.values) ``` The following code prints
The problem is that if I want to append to the zarr archive, like so: ```python import zarr ds = zarr.open('ds', mode='a') da_new = xr.DataArray(['barbar']) ds.da.append(da_new) ds = xr.open_zarr('ds') print(ds.da.values) ``` It prints If I want to specify the encoding with the maximum length, e.g:
It solves the length problem, but now my strings are kept as bytes:
It is not taken into account. The zarr encoding is The solution with |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2789/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 636480145 | MDU6SXNzdWU2MzY0ODAxNDU= | 4141 | xarray.where() drops attributes | davidbrochart 4711805 | closed | 0 | 3 | 2020-06-10T19:06:32Z | 2022-01-19T19:35:41Z | 2022-01-19T19:35:41Z | CONTRIBUTOR | MCVE Code Sample```python import xarray as xr da = xr.DataArray(1) da.attrs['foo'] = 'bar' xr.where(da==0, -1, da).attrs shows: {}``` Expected Output
Problem DescriptionI would expect the attributes to remain in the data array. VersionsOutput of <tt>xr.show_versions()</tt>INSTALLED VERSIONS ------------------ commit: None python: 3.8.2 | packaged by conda-forge | (default, Apr 24 2020, 08:20:52) [GCC 7.3.0] python-bits: 64 OS: Linux OS-release: 5.4.0-33-generic machine: x86_64 processor: x86_64 byteorder: little LC_ALL: None LANG: en_US.UTF-8 LOCALE: en_US.UTF-8 libhdf5: None libnetcdf: None xarray: 0.15.1 pandas: 1.0.4 numpy: 1.18.4 scipy: 1.4.1 netCDF4: None pydap: None h5netcdf: None h5py: None Nio: None zarr: None cftime: None nc_time_axis: None PseudoNetCDF: None rasterio: 1.1.4 cfgrib: None iris: None bottleneck: None dask: 2.16.0 distributed: None matplotlib: 3.2.1 cartopy: None seaborn: None numbagg: None setuptools: 46.2.0 pip: 20.1 conda: None pytest: None IPython: 7.14.0 sphinx: 3.0.4 |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4141/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 777670351 | MDU6SXNzdWU3Nzc2NzAzNTE= | 4756 | feat: reindex multiple DataArrays | davidbrochart 4711805 | open | 0 | 1 | 2021-01-03T16:23:01Z | 2021-01-03T19:05:03Z | CONTRIBUTOR | When e.g. creating a da1 = xr.DataArray([[0, 1, 2], [3, 4, 5], [6, 7, 8]], coords=[[0, 1, 2], [0, 1, 2]], dims=['x', 'y']).rename('da1')
da2 = xr.DataArray([[0, 1, 2], [3, 4, 5], [6, 7, 8]], coords=[[1.1, 2.1, 3.1], [1.1, 2.1, 3.1]], dims=['x', 'y']).rename('da2')
da1.plot.imshow()
da2.plot.imshow()
```python import numpy as np from functools import reduce def reindex_all(arrays, dims, tolerance): coords = {} for dim in dims: coord = reduce(np.union1d, [array[dim] for array in arrays[1:]], arrays[0][dim]) diff = coord[:-1] - coord[1:] keep = np.abs(diff) > tolerance coords[dim] = np.append(coord[:-1][keep], coord[-1]) reindexed = [array.reindex(coords, method='nearest', tolerance=tolerance) for array in arrays] return reindexed da1r, da2r = reindex_all([da1, da2], ['x', 'y'], 0.2)
dsr = xr.Dataset({'da1': da1r, 'da2': da2r})
dsr['da1'].plot.imshow()
dsr['da2'].plot.imshow()
```
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/4756/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue | ||||||||
| 393742068 | MDU6SXNzdWUzOTM3NDIwNjg= | 2628 | Empty plot with pcolormesh in the notebook | davidbrochart 4711805 | closed | 0 | 3 | 2018-12-23T11:21:48Z | 2020-12-05T05:06:36Z | 2020-12-05T05:06:36Z | CONTRIBUTOR | Code Sample```python import numpy as np import xarray as xr import matplotlib.pyplot as plt %matplotlib inline a = np.ones((4000, 4000), dtype=np.uint8) a[:1000, :1000] = 0 lat = np.array([0-i for i in range(a.shape[0])]) lon = np.array([0+i for i in range(a.shape[1])]) da = xr.DataArray(a, coords=[lat, lon], dims=['lat', 'lon']) da.plot.pcolormesh() ``` Problem descriptionThe code above shows an empty plot in a notebook (but not in the console). Expected OutputIf I replace Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2628/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 736092268 | MDExOlB1bGxSZXF1ZXN0NTE1MzY2NzA3 | 4564 | Add xtrude project to documentation | davidbrochart 4711805 | closed | 0 | 1 | 2020-11-04T12:54:20Z | 2020-11-04T16:00:34Z | 2020-11-04T15:57:11Z | CONTRIBUTOR | 0 | pydata/xarray/pulls/4564 | {
"url": "https://api.github.com/repos/pydata/xarray/issues/4564/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | ||||||
| 649683292 | MDExOlB1bGxSZXF1ZXN0NDQzMzEzNDMz | 4192 | Fix typo | davidbrochart 4711805 | closed | 0 | 1 | 2020-07-02T06:51:56Z | 2020-07-02T12:15:07Z | 2020-07-02T12:09:38Z | CONTRIBUTOR | 0 | pydata/xarray/pulls/4192 | {
"url": "https://api.github.com/repos/pydata/xarray/issues/4192/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | ||||||
| 615837634 | MDExOlB1bGxSZXF1ZXN0NDE2MDY2MTEz | 4051 | Add xarray-leaflet to the visualization projects | davidbrochart 4711805 | closed | 0 | 3 | 2020-05-11T12:13:53Z | 2020-05-11T20:01:30Z | 2020-05-11T14:54:28Z | CONTRIBUTOR | 0 | pydata/xarray/pulls/4051 | {
"url": "https://api.github.com/repos/pydata/xarray/issues/4051/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | ||||||
| 395384938 | MDU6SXNzdWUzOTUzODQ5Mzg= | 2644 | DataArray concat with tolerance | davidbrochart 4711805 | closed | 0 | 3 | 2019-01-02T21:23:21Z | 2019-08-15T15:15:26Z | 2019-08-15T15:15:26Z | CONTRIBUTOR | I would like to concatenate many
And I would get: ``` <xarray.DataArray (z: 2, x: 3, y: 3)> array([[[ 0., 1., nan], [ 2., 3., nan], [nan, nan, nan]], Coordinates: * x (x) float64 0 1 2.1 * y (y) float64 0 1 2.1 Dimensions without coordinates: z ``` @jhamman suggested to use
Is there another work around? Do you think it would be worth having this feature in |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2644/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 467805570 | MDExOlB1bGxSZXF1ZXN0Mjk3Mzc0NDIw | 3123 | to_zarr(append_dim='dim0') doesn't need mode='a' | davidbrochart 4711805 | closed | 0 | 4 | 2019-07-14T07:36:11Z | 2019-07-29T18:49:12Z | 2019-07-29T15:54:45Z | CONTRIBUTOR | 0 | pydata/xarray/pulls/3123 |
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3123/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 467338176 | MDU6SXNzdWU0NjczMzgxNzY= | 3100 | Append to zarr redundant with mode='a' | davidbrochart 4711805 | closed | 0 | 3 | 2019-07-12T10:21:04Z | 2019-07-29T15:54:45Z | 2019-07-29T15:54:45Z | CONTRIBUTOR | When appending to a zarr store, we need to set |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 385155383 | MDExOlB1bGxSZXF1ZXN0MjM0MTg4NTUx | 2578 | Fix typo | davidbrochart 4711805 | closed | 0 | 1 | 2018-11-28T08:34:40Z | 2019-07-14T07:25:01Z | 2018-11-28T19:26:55Z | CONTRIBUTOR | 0 | pydata/xarray/pulls/2578 | {
"url": "https://api.github.com/repos/pydata/xarray/issues/2578/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | ||||||
| 463430234 | MDExOlB1bGxSZXF1ZXN0MjkzOTExNDgw | 3076 | Fix error message | davidbrochart 4711805 | closed | 0 | 1 | 2019-07-02T20:52:11Z | 2019-07-14T07:24:50Z | 2019-07-02T21:27:41Z | CONTRIBUTOR | 0 | pydata/xarray/pulls/3076 |
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3076/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | pull | |||||
| 467267153 | MDU6SXNzdWU0NjcyNjcxNTM= | 3099 | Interpolation doesn't apply on time coordinate | davidbrochart 4711805 | closed | 0 | 1 | 2019-07-12T07:37:18Z | 2019-07-13T15:05:39Z | 2019-07-13T15:05:39Z | CONTRIBUTOR | MCVE Code Sample```python In [1]: import numpy as np ...: import pandas as pd ...: import xarray as xr In [2]: da = xr.DataArray([1, 2], [('time', pd.date_range('2000-01-01', '2000-01-02', periods=2))])
...: da In [3]: da.interp(time=da.time-np.timedelta64(1, 'D')) Problem DescriptionThe data has been interpolated, but not the time coordinate. Expected OutputWhen we explicitly get the values of the time coordinate, it works fine:
Output of
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 463928027 | MDU6SXNzdWU0NjM5MjgwMjc= | 3078 | Auto-generated API documentation | davidbrochart 4711805 | closed | 0 | 2 | 2019-07-03T19:57:51Z | 2019-07-03T20:02:11Z | 2019-07-03T20:00:35Z | CONTRIBUTOR | For instance in http://xarray.pydata.org/en/stable/generated/xarray.apply_ufunc.html, there is no space between the parameters and their type description, e.g. |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/3078/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 415614806 | MDU6SXNzdWU0MTU2MTQ4MDY= | 2793 | Fit bounding box to coarser resolution | davidbrochart 4711805 | open | 0 | 2 | 2019-02-28T13:07:09Z | 2019-04-11T14:37:47Z | CONTRIBUTOR | When using coarsen, we often need to align the original DataArray with the coarser coordinates. For instance: ```python import xarray as xr import numpy as np da = xr.DataArray(np.arange(4*4).reshape(4, 4), coords=[np.arange(4, 0, -1) + 0.5, np.arange(4) + 0.5], dims=['lat', 'lon']) <xarray.DataArray (lat: 4, lon: 4)>array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]])Coordinates:* lat (lat) float64 4.5 3.5 2.5 1.5* lon (lon) float64 0.5 1.5 2.5 3.5da.coarsen(lat=2, lon=2).mean() <xarray.DataArray (lat: 2, lon: 2)>array([[ 2.5, 4.5],[10.5, 12.5]])Coordinates:* lat (lat) float64 4.0 2.0* lon (lon) float64 1.0 3.0
da = adjust_bbox(da, {'lat': (2, -1), 'lon': (2, 1)}) <xarray.DataArray (lat: 6, lon: 4)>array([[ 0., 0., 0., 0.],[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[12., 13., 14., 15.],[ 0., 0., 0., 0.]])Coordinates:* lat (lat) float64 5.5 4.5 3.5 2.5 1.5 0.5* lon (lon) float64 0.5 1.5 2.5 3.5da.coarsen(lat=2, lon=2).mean() <xarray.DataArray (lat: 3, lon: 2)>array([[0.25, 1.25],[6.5 , 8.5 ],[6.25, 7.25]])Coordinates:* lat (lat) float64 5.0 3.0 1.0* lon (lon) float64 1.0 3.0
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/2793/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue |
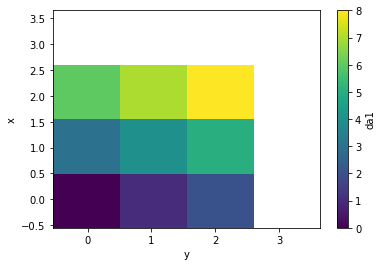
 I have not found something equivalent. If you think this is worth it, I could try and send a PR to implement such a feature.
I have not found something equivalent. If you think this is worth it, I could try and send a PR to implement such a feature.{kind=link}
{kind=link}
{kind=link}
{kind=link}
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[active_lock_reason] TEXT,
[draft] INTEGER,
[pull_request] TEXT,
[body] TEXT,
[reactions] TEXT,
[performed_via_github_app] TEXT,
[state_reason] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);