issues
3 rows where repo = 13221727 and user = 12818667 sorted by updated_at descending
This data as json, CSV (advanced)
Suggested facets: comments, created_at (date), updated_at (date), closed_at (date)
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at ▲ | closed_at | author_association | active_lock_reason | draft | pull_request | body | reactions | performed_via_github_app | state_reason | repo | type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1249638836 | I_kwDOAMm_X85Ke_m0 | 6640 | to_zarr fails for large dimensions; sensitive to exact dimension size and chunk size | JamiePringle 12818667 | closed | 0 | 5 | 2022-05-26T14:22:20Z | 2023-10-14T20:29:50Z | 2023-10-14T20:29:49Z | NONE | What happened?Using dask 2022.05.0, zarr 2.11.3 and xarray 2022.3.0, When creating a large empty dataset and trying to save it in the zarr data format with to_zarr, it fails with the following error. Frankly, I am not sure if the problem is with Xarray or Zarr, but as documented in the attached code, when I create the same dataset with Zarr, it works just fine. ``` File ~/anaconda3/envs/py3_parcels_mpi_bleedingApr2022/lib/python3.9/site-packages/zarr/core.py:2101, in Array._decode_chunk(self, cdata, start, nitems, expected_shape) 2099 # ensure correct chunk shape 2100 chunk = chunk.reshape(-1, order='A') -> 2101 chunk = chunk.reshape(expected_shape or self._chunks, order=self._order) 2103 return chunk ValueError: cannot reshape array of size 234506 into shape (235150,) ``` To show that this is not a zarr issue, I have made the same output directly with zarr in the example code below. It is in the "else" clause in the code. Note well: I have included a value of numberOfDrifters that has the problem, and one that does not. Please see the comments where numberOfDrifters is defined. What did you expect to happen?I expected a zarr dataset to be created. I cannot solve the problem with a chunk size of 1 for memory issues. I would prefer to create the zarr dataset with xarray so it has the metadata to be easily loaded into xarray. Minimal Complete Verifiable Example```Python from numpy import * import xarray as xr import dask import zarr dtype=float32 chunkSize=10000 maxNumObs=1 numberOfDrifters=120396431 #2008 This size WORKSnumberOfDrifters=120067029 #2007 This size FAILS if True, make zarr with xarrayif True: #make xarray data set, then write to zarr coords={'traj':(['traj'],arange(numberOfDrifters)),'obs':(['obs'],arange(maxNumObs))} emptyArray=dask.array.empty(shape=(numberOfDrifters,maxNumObs),dtype=dtype,chunks=(chunkSize,maxNumObs)) var='time' data_vars={} attrs={} data_vars[var]=(['traj','obs'],emptyArray,attrs) dataOut=xr.Dataset(data_vars,coords,{}) print('done defining data set, now writing') else: #make with zarr store=zarr.DirectoryStore('dataPaths/jnk_makeWithZarr.zarr') root=zarr.group(store=store) root.empty(shape=(numberOfDrifters,maxNumObs),name='time',dtype=dtype,chunks=(chunkSize,maxNumObs)) print('done writting') zarrInZarr=zarr.open('dataPaths/jnk_makeWithZarr.zarr','r') print('done opening') ``` MVCE confirmation
Relevant log output
Anything else we need to know?No response Environment
INSTALLED VERSIONS
------------------
commit: None
python: 3.9.12 | packaged by conda-forge | (main, Mar 24 2022, 23:22:55)
[GCC 10.3.0]
python-bits: 64
OS: Linux
OS-release: 5.13.0-41-generic
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: ('en_US', 'UTF-8')
libhdf5: 1.12.1
libnetcdf: 4.8.1
xarray: 2022.3.0
pandas: 1.4.1
numpy: 1.20.3
scipy: 1.8.0
netCDF4: 1.5.8
pydap: None
h5netcdf: None
h5py: None
Nio: None
zarr: 2.11.3
cftime: 1.6.0
nc_time_axis: None
PseudoNetCDF: None
rasterio: None
cfgrib: None
iris: None
bottleneck: None
dask: 2022.05.0
distributed: 2022.5.0
matplotlib: 3.5.1
cartopy: 0.20.2
seaborn: None
numbagg: None
fsspec: 2022.02.0
cupy: None
pint: None
sparse: None
setuptools: 61.2.0
pip: 22.0.4
conda: None
pytest: 7.1.1
IPython: 8.2.0
sphinx: None
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/6640/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
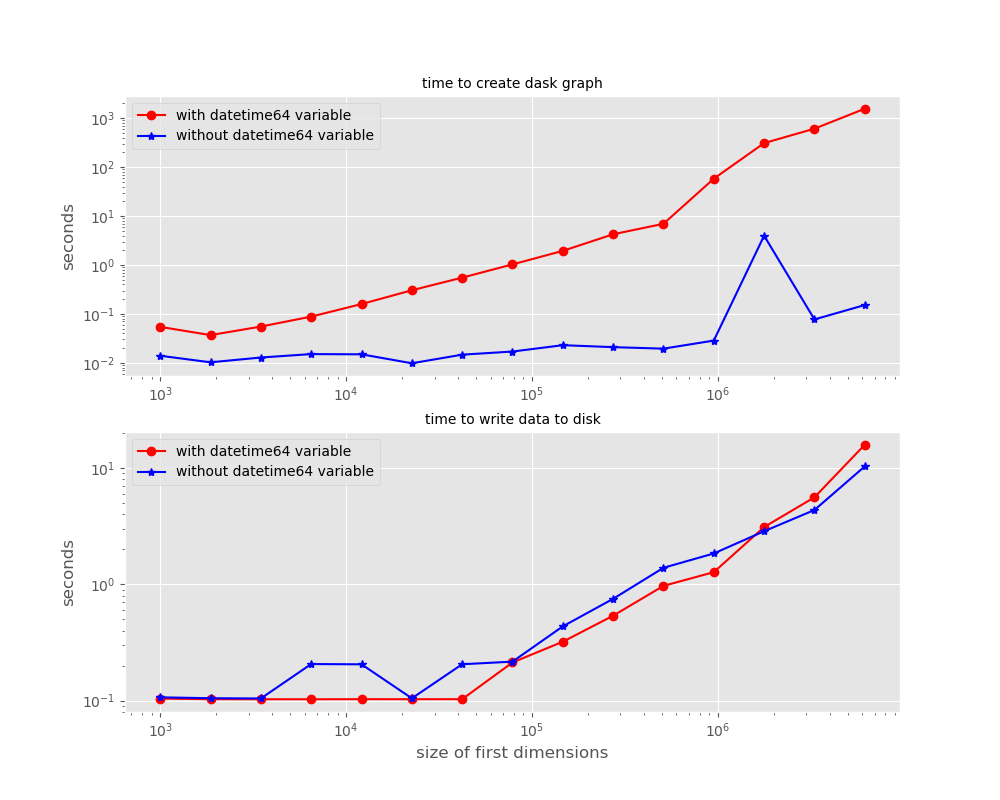
| 1371466778 | I_kwDOAMm_X85Rvuwa | 7028 | .to_zarr() or .to_netcdf slow and uses excess memory when datetime64[ns] variable in output; a reproducible example | JamiePringle 12818667 | closed | 0 | 3 | 2022-09-13T13:32:29Z | 2022-11-03T15:40:53Z | 2022-11-03T15:40:52Z | NONE | What happened?This bug report is a reproducible example with code of an issue that may be in #7018, #2912 and other bug reports reporting slow performance and memory exhaustion when using .to_zarr() or .to_netcdf(). I think this has been hard to track down because it only occurs for large data sets. I have included code that replicates the problem without the need for downloading a large dataset. The problem is that saving a xarray dataset which includes a variable with type datetime64[ns] is several orders of magnitude slower (!!) and uses a great deal of memory (!!) relative to the same dataset where that variable has another type. The work around is obvious -- turn off time decoding and treat time as a float64. But this is in-elegant, and I think this problem has lead to many un-answered questions on the issues page, such as the one above. If I save a dataset whose structure (based on my use case, the ocean-parcels Lagrangian particle tracker) is:
To recreate this graph, and to see a very simple code that replicates this problem, see the attached python code. Note that the directory you run it in should have at least 30Gb free for the data set it writes, and for machines with less than 256Gb of memory, it will crash before completing after exhausting the memory. However, the last figure will be saved in jnk_out.png, and you can always change the largest size it attempts to create. SmallestExample_zarrOutProblem.zip What did you expect to happen?I expect that the time to save a dataset with .to_zarr or .to_netcdf does not change dramatically if one of the variables has a datetime64[ns] type. Minimal Complete Verifiable Example```Python this code is also included as a zip file above.import xarray as xr from pylab import * from numpy import * from glob import globfrom os import pathimport time import dask from dask.diagnostics import ProgressBar import shutil import pickle this is a minimal code that illustrates issue with .to_zarr() or .to_netcdf when writing a dataset with datetime64 dataoutputDir is the name of the zarr output; it should be set to a location on a fast filesystem with enough spaceoutputDir='./testOut.zarr' def testToZarr(dimensions,haveTimeType=True): '''This code writes out an empty dataset with the dimensions specified in the "dimensions" arguement, and returns the time it took to create the dask delayed object and the time it took to compute the delayed object. now lets do some benchmarkingif name == "main": figure(1,figsize=(10.0,8.0)) clf() style.use('ggplot') ``` MVCE confirmation
Relevant log outputNo response Anything else we need to know?No response EnvironmentNote -- I see the same thing on my linux machine
INSTALLED VERSIONS
------------------
commit: None
python: 3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:41:22) [Clang 13.0.1 ]
python-bits: 64
OS: Darwin
OS-release: 21.6.0
machine: arm64
processor: arm
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: ('en_US', 'UTF-8')
libhdf5: None
libnetcdf: None
xarray: 2022.6.0
pandas: 1.4.3
numpy: 1.23.2
scipy: 1.9.0
netCDF4: None
pydap: None
h5netcdf: None
h5py: None
Nio: None
zarr: 2.12.0
cftime: None
nc_time_axis: None
PseudoNetCDF: None
rasterio: None
cfgrib: None
iris: None
bottleneck: None
dask: 2022.8.1
distributed: 2022.8.1
matplotlib: 3.5.3
cartopy: 0.20.3
seaborn: None
numbagg: None
fsspec: 2022.7.1
cupy: None
pint: None
sparse: None
flox: None
numpy_groupies: None
setuptools: 65.3.0
pip: 22.2.2
conda: None
pytest: None
IPython: 8.4.0
sphinx: None
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/7028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
completed | xarray 13221727 | issue | ||||||
| 1358960570 | I_kwDOAMm_X85RABe6 | 6976 | dataset.sel inconsistent results when argument is a list or a slice. | JamiePringle 12818667 | open | 0 | 5 | 2022-09-01T14:40:34Z | 2022-09-02T14:13:27Z | NONE | What happened?I am not sure if what I report is a bug; however, it is certainly not what I expect from a careful reading of the documentation, and I wonder if it is leading to some issues I describe below. I am working with a large dataset produced by merging the output of runs made by different MPI processes. There are two coordinates, ("trajectory","obs"). All of the "obs" in the dataset are in order, but the "trajectory" coordinate is not in order. I made a smaller dataset that illustrates the issue below by reducing the number of "obs" from 250 to 2; this dataset can be found at http://oxbow.sr.unh.edu/data/smallExample.zarr.zip . This dataset looks like:
If I want an ordered set of trajectories, say trajectories [1,2,3,4,5,6,7,8,9,10], and I do this with But if I use the slice operator to specify what I want, I get something very different: I have had all sorts of issues with the full dataset, including .to_zarr(dataset, compute=False) failing to return a delayedObject because it used all the memory, What did you expect to happen?See above for full descriptions Minimal Complete Verifiable Example```Python get data from http://oxbow.sr.unh.edu/data/smallExample.zarr.zipdataIn=xr.open_zarr('smallExample.zarr') print(dataIn.sel(trajectory=arange(1,11))) print(dataIn.sel(trajectory=slice(1,11))) ``` MVCE confirmation
Relevant log outputNo response Anything else we need to know?No response Environment
INSTALLED VERSIONS
------------------
commit: None
python: 3.10.5 | packaged by conda-forge | (main, Jun 14 2022, 07:04:59) [GCC 10.3.0]
python-bits: 64
OS: Linux
OS-release: 5.15.0-46-generic
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: ('en_US', 'UTF-8')
libhdf5: 1.12.2
libnetcdf: 4.8.1
xarray: 2022.6.0
pandas: 1.4.3
numpy: 1.23.2
scipy: 1.9.0
netCDF4: 1.6.0
pydap: None
h5netcdf: None
h5py: None
Nio: None
zarr: 2.12.0
cftime: 1.6.1
nc_time_axis: None
PseudoNetCDF: None
rasterio: None
cfgrib: None
iris: None
bottleneck: None
dask: 2022.8.1
distributed: 2022.8.1
matplotlib: 3.5.3
cartopy: 0.20.3
seaborn: None
numbagg: None
fsspec: 2022.7.1
cupy: None
pint: None
sparse: None
flox: None
numpy_groupies: None
setuptools: 65.2.0
pip: 22.2.2
conda: None
pytest: 7.1.2
IPython: 8.4.0
sphinx: None
|
{
"url": "https://api.github.com/repos/pydata/xarray/issues/6976/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
xarray 13221727 | issue |
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[active_lock_reason] TEXT,
[draft] INTEGER,
[pull_request] TEXT,
[body] TEXT,
[reactions] TEXT,
[performed_via_github_app] TEXT,
[state_reason] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);