issues: 950882492
This data as json
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at | closed_at | author_association | active_lock_reason | draft | pull_request | body | reactions | performed_via_github_app | state_reason | repo | type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 950882492 | MDU6SXNzdWU5NTA4ODI0OTI= | 5629 | Polyfit performance on large datasets - Suboptimal dask task graph | 14314623 | open | 0 | 15 | 2021-07-22T17:19:52Z | 2023-01-24T20:19:19Z | CONTRIBUTOR | What happened: I am trying to calculate a linear trend over a large climate model simulation. I use rechunker to chunk the data along the horizontal dimensions and make sure that the time dimension (along which I want to calculate the fit) is not chunked. In my realistic example, this blows up the memory of my workers. What you expected to happen: I expected this to work very smoothly because it should be embarassingly parallel (no information of sourrounding chunks is needed and the time dimension is complete in each chunk). Minimal Complete Verifiable Example: I think this minimal example shows that the task graph created is not ideal
When I apply polyfit I get this
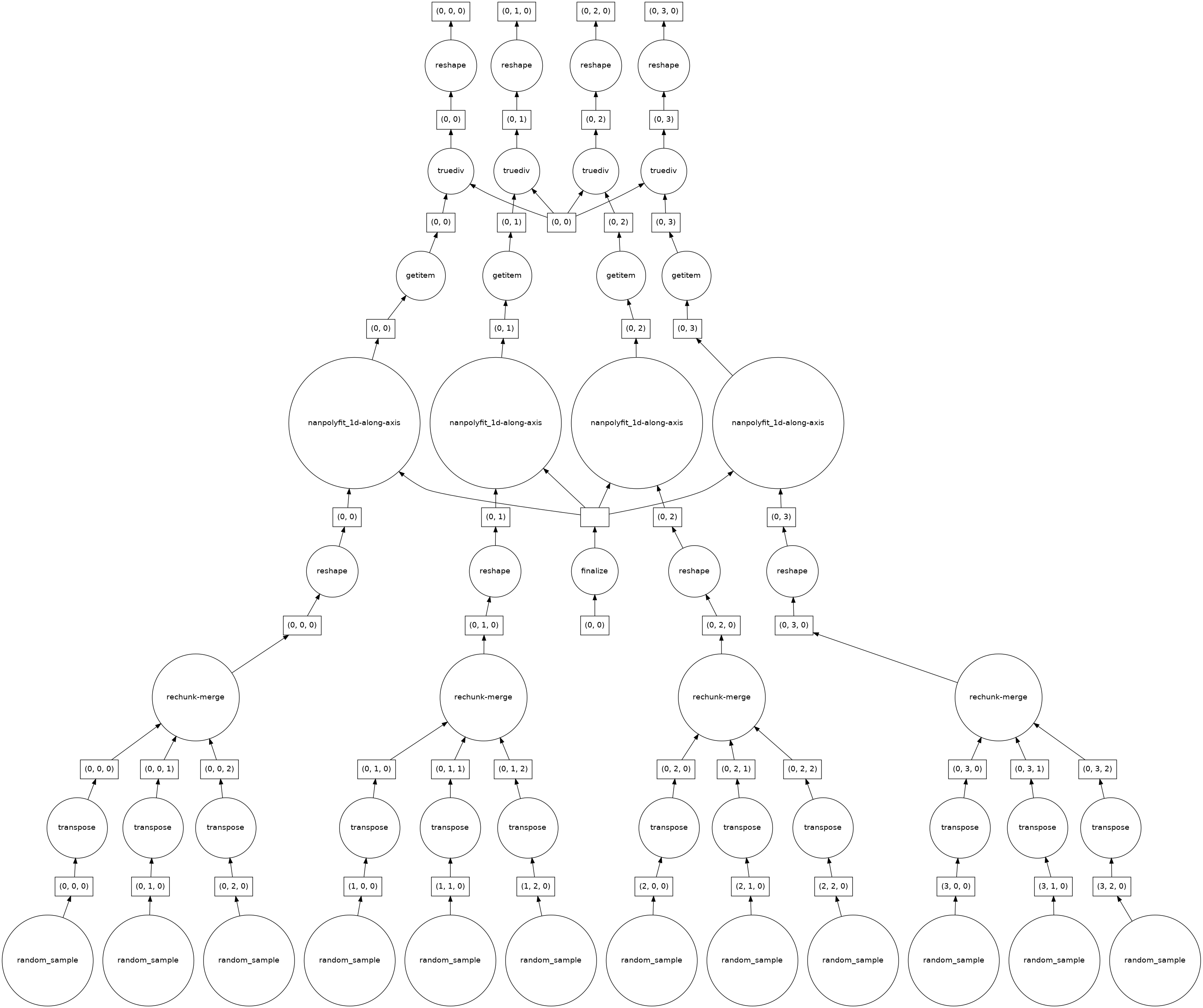
Now the number of chunks has decreased to 4? I am not sure why, but this indicates to me that my problem might be related to #4554. When I look at the task graph it seems that this explains why for very large dataset the computation blows up:
As I said before I would expect this calculation to be fully parallelizable, but there seems to be some aggregation/rechunking steps in the bottom layer. How 'bad' these get (e.g. how many input chunks get lumped together in the cc @TomNicholas Anything else we need to know?: Environment: Output of <tt>xr.show_versions()</tt>INSTALLED VERSIONS ------------------ commit: None python: 3.8.8 | packaged by conda-forge | (default, Feb 20 2021, 16:22:27) [GCC 9.3.0] python-bits: 64 OS: Linux OS-release: 5.4.89+ machine: x86_64 processor: x86_64 byteorder: little LC_ALL: C.UTF-8 LANG: C.UTF-8 LOCALE: en_US.UTF-8 libhdf5: 1.10.6 libnetcdf: 4.7.4 xarray: 0.17.0 pandas: 1.2.4 numpy: 1.20.2 scipy: 1.6.2 netCDF4: 1.5.6 pydap: installed h5netcdf: 0.11.0 h5py: 3.2.1 Nio: None zarr: 2.7.1 cftime: 1.4.1 nc_time_axis: 1.2.0 PseudoNetCDF: None rasterio: 1.2.2 cfgrib: 0.9.9.0 iris: None bottleneck: 1.3.2 dask: 2021.04.1 distributed: 2021.04.1 matplotlib: 3.4.1 cartopy: 0.19.0 seaborn: None numbagg: None pint: 0.17 setuptools: 49.6.0.post20210108 pip: 20.3.4 conda: None pytest: None IPython: 7.22.0 sphinx: None |
{
"url": "https://api.github.com/repos/pydata/xarray/issues/5629/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
13221727 | issue |